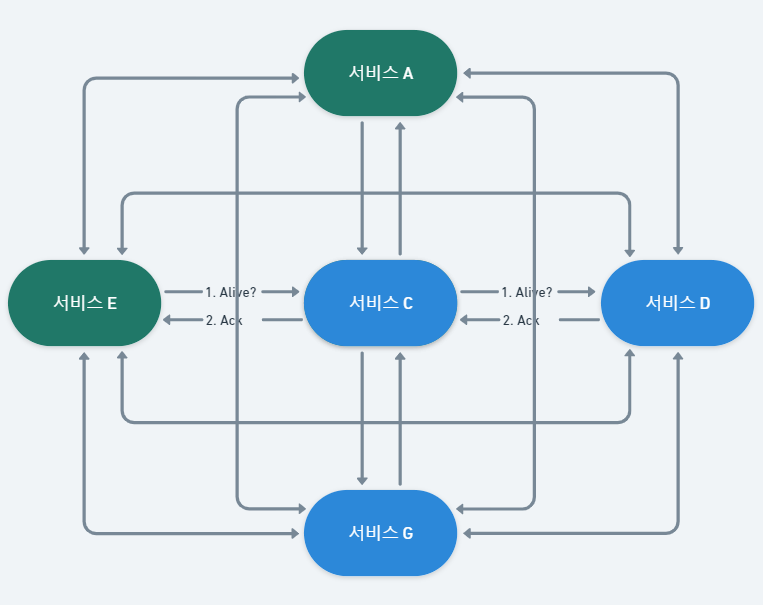
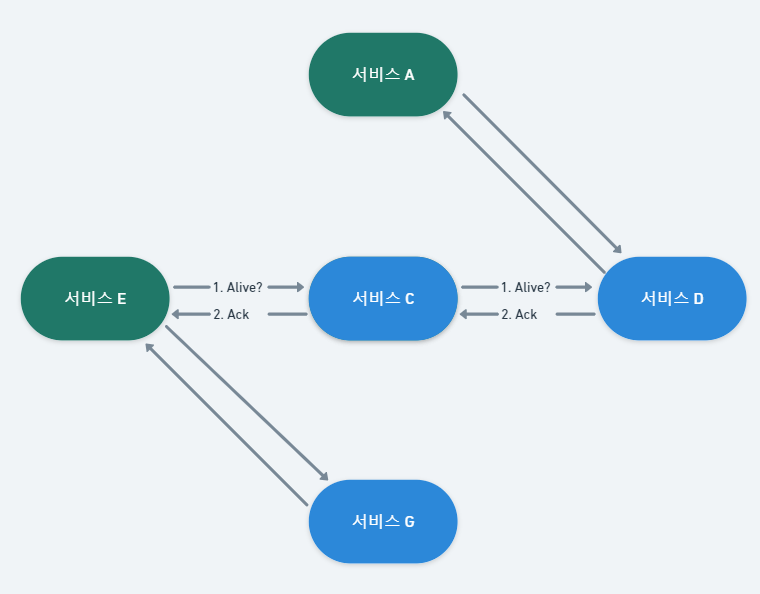
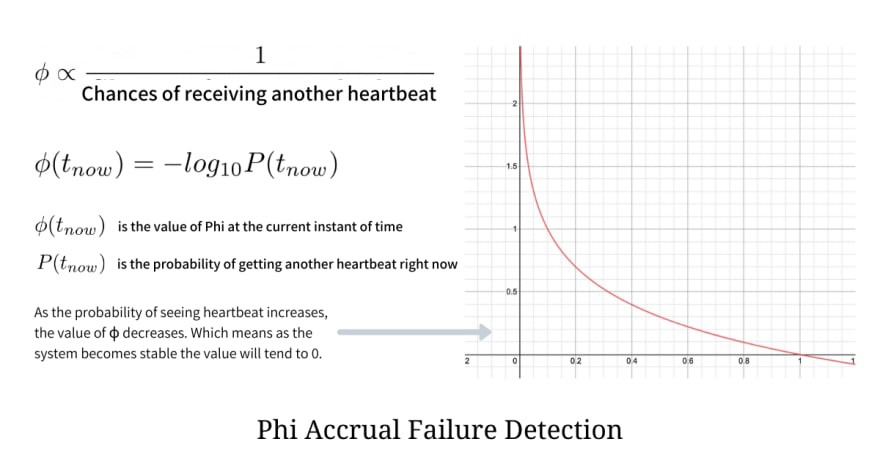
이 글은 특정 구현에 종속되는 내용을 제외한 이론 위주의 정리 글입니다.
Redis Persistence
Redis는 가지고 있는 데이터를 장애 발생 시 복구할 수 있도록 데이터를 영속화하는 방법을 제공합니다.
Redis 데이터 영속화는 관리하는 비즈니스 데이터의 성향과 중요도에 따라 사용하거나, 하지 않을 수 있습니다. 상황을 고려하지 않고 AOF의 Always 전략 등을 사용하는 행위는 Redis의 성능 하락과 응답 지연 문제를 심화시킬 수 있기 때문에 잘 고려하여야 합니다.
영속화를 사용하는 경우 Redis Server의 서비스 중단을 방지하기 위해 Child Background Process를 사용하는 것이 필수적이며, Process fork로 인한 메모리 사용량, 발생하는 Disk I/O 빈도와 저장된 파일 용량 등을 확인하여야 합니다.
RDB : Redis Database Backup
현재 Redis의 메모리에 존재하는 데이터의 스냅샷을 남기는 방식입니다. 즉 key와 value 형태의 값을 그대로 기록하는 방식입니다.
Key1 -> value
count -> 22
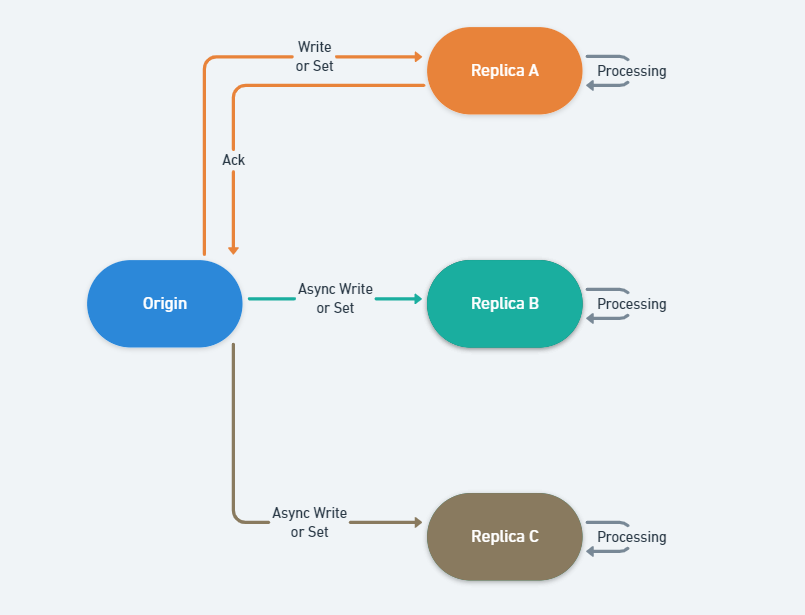
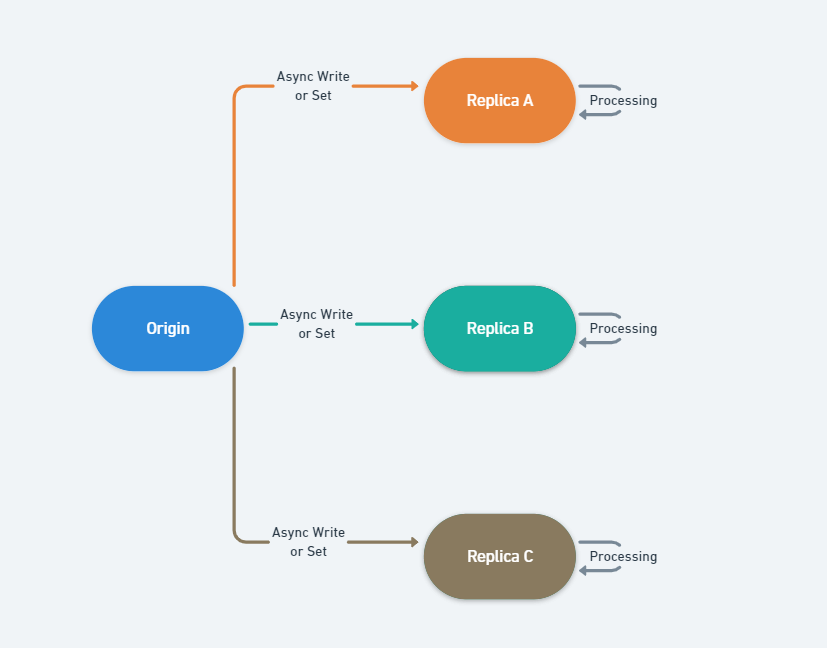
이 방식은 AOF 파일보다 작은 용량, 짧은 쓰기 지연 시간과 데이터 복구 시간을 가지고 있는 점이 특징입니다. Redis Replication 수행 시 사용되기도 하는 포맷이며 기본적으로 Origin에서 생성된 RDB 파일을 Replica node에게 전송하고, Replica에서는 임시 RDB 파일을 만들어 파일에 쓴 다음 동기화하는 방식을 취하고 있습니다.
- RDB 파일은 AOF 파일보다 데이터 유실이 발생하기 쉽습니다. 스냅샷은 일정 주기마다 기록되기 때문에 최대 지정된 주기 만큼의 데이터를 유실할 가능성이 있습니다.
Replication 부하를 줄이기 위해 RDB를 Replica가 설치된 서버에서 수행할 수도 있습니다.
redis-conf에서 save 속성을 설정한 대로 RDB를 주기적으로 수행하며 필요하다면 SAVE, BGSAVE Command를 통해 수동으로 수행할 수 있습니다.
- SAVE를 사용한 경우에는 모든 사용자 요청 및 작업을 중지하고 현재 동작 중인 프로세스(main)에서 RDB 파일을 생성하게 됩니다. - 비권장
- BGSAVE를 사용한 경우에는 현재 프로세스는 계속 요청을 처리하고 fork를 통해 자식 프로세스를 생성하여 RDB 파일을 생성합니다. - 권장
BGSAVE 방식으로 fork를 진행한 후 데이터를 기록할 때 Linux의 특성상 COW에 의해 메모리 사용량이 최대 2배까지 늘어날 수 있습니다.
이는 Process fork를 통해 동작하여 처음에는 부모와 자식 프로세스가 동일한 메모리 영역을 공유하고 있지만, 부모 프로세스에서 데이터를 변경하면 해당 데이터는 다른 메모리 영역으로 복사되어 “부모에게만 참조되는” 상황 때문입니다.
Redis의 기본 설정에 의해 BGSAVE Command를 통한 RDB 작업이 실패한 경우 Redis Server가 Client의 쓰기 요청을 처리하지 않는 상황이 발생합니다. 이를 방지하기 위해 stop-writes-on-bgsave-error 설정 값을 no로 설정하여야 합니다.
- no로 설정한 경우에는 Client 요청을 정상적으로 처리하게 되고 실패한 RDB를 다시 수행하지 않습니다.
- 디스크 용량이나 깨짐, 사용 권한 등의 문제로 RDB가 실패할 수 있음을 인지하고 있어야 합니다.
관련 속성에는 dump 파일 생성 시 압축하도록 하는 rdbcompression (bool), 데이터 유효성 검사가 진행되도록 하는 rdbchecksum (bool), 파일 이름을 지정하는 dbfilename과 파일 저장 위치를 지정하는 dir 속성이 있습니다.
AOF : Append Only File
데이터를 변경하는 모든 Redis Command를 파일에 저장하는 방식입니다. Client에 의해 수행되었던 모든 데이터 추가, 수정 Command를 저장하고 또한 Text 파일 형태로 제공하여 쉽게 식별 가능하고 활용할 수 있기 때문에 장애 발생 시 최신 데이터를 복구함에 있어서 많은 이점을 가지는 방법입니다.
- 커지는 파일 용량을 잘 고려해야 하며, Disk I/O 횟수나 비용으로 인해 큰 성능 저하를 일으킬 수 있는 방법입니다.
set key1 hello
set key1 value
set count 22
del key2RDB 동작보다 우선순위가 높아 먼저 수행되고, 매 요청마다 수행됩니다. Client가 업데이트 명령을 요청하면 Redis는 먼저 해당 명령을 파일에 저장하고 파일 쓰기가 완료되었을 때 해당 명령을 실행해서 내용을 추가합니다.
이 방식은 redis-conf에 appendonly를 설정하면 수행하며, 필요하다면 BGREWRITEAOF Command를 통해 수동으로 AOF 파일을 재 작성할 수 있습니다.
또한 Append라는 의미에 맞게 매번 파일에 수행된 Command와 Metadata를 추가합니다. 그렇기에 파일 용량이 시간이 지남에 따라 계속 커지게 됩니다. 만약 OS에서 설정한 파일 용량 임계치를 넘어선다면 AOF 파일 기록이 중단되거나 Redis Server 재 시작 시 I/O 핸들러를 열거나 읽어오는 시간 등 때문에 서비스 제공 시간이 지연될 수 있습니다.
이를 방지하기 위해 rewrite를 지속적으로 수행하여야 하는데 이 작업 또한 Disk I/O 작업이기 때문에 Redis 지연 이슈를 발생시킬 수 있습니다.
- 위에서 설명한 appendfsync 전략과 auto-aof-rewrite-percentage, auto-aof-rewrite-min-size 속성을 조정하여 이를 알맞게 구성하여야 합니다.
AOF disk write(fsync, fdatasync) 전략에는 Always, Everysec, No가 존재합니다.
- Always는 write를 수행할 때마다 fsync를 수행하는 방식으로 데이터를 완전히 보전하기 위해 사용하는 전략입니다. 쓰기 방식 중 성능이 제일 좋지 않아 DISK base DBMS를 사용하는 것과 비슷한 처리 성능을 가지게 됩니다.
- Everysec는 매 초마다 fsync를 수행하는 방식으로 성능과 데이터 보존을 어느 정도 지킬 수 있는 최선의 선택입니다. (권장 방식)
- 해당 AOF를 사용하고 있다면 최대 1초의 데이터 유실이 발생할 수 있습니다.
- No는 Redis가 아닌 OS가 fsync를 수행하는 방식으로 Linux의 경우 30초마다 동기화를 수행합니다. 이때 Linux는 fsync가 아닌 fdatasync 방식으로 수행하는데 이는 파일 접근 시간, modify time, 파일 용량 등의 Metadata를 저장하지 않는 방식으로 더 빠른 성능을 보장합니다.
RDB의 경우 백업은 필요하나 데이터 손실이 발생해도 무관한 경우에 활용할 수 있고(단순 콘텐츠 캐싱 등), AOF의 경우 장애 상황 직전까지 모든 데이터가 보장되어야 할 중요한 비즈니스 데이터를 다룰 때 적용하게 됩니다.
비관적으로 한 작업의 실패를 가정하는 경우 RDB & AOF를 동시에 사용하여 안전하게 갈 수도 있습니다.
운영 시 주의할 점
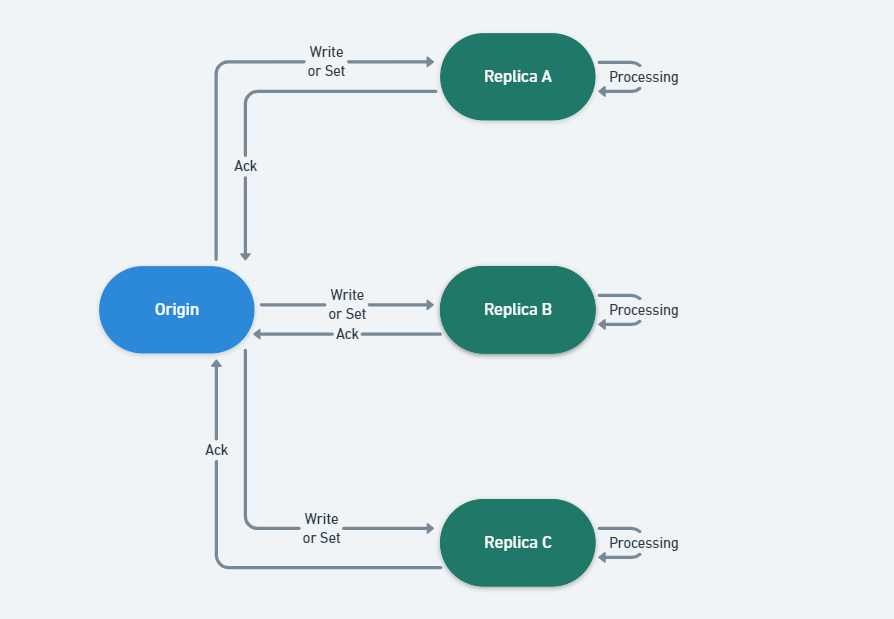
비어있는 Master와 데이터를 가진 Slave가 서로 간의 Replication을 수행하지 않도록 할 것
Master와 Slave 사이의 최초 동기화 시점에는 서로 간의 데이터 Sync를 맞추려는 작업을 수행하게 됩니다. 만약 Master가 장애 발생으로 인해 아무 데이터도 없이 복구 조치 되었다면, 이와 연결된 Slave에도 emptyDB라는 함수가 호출되어 가지고 있는 모든 정보를 정리하게 됩니다.
// Sync Process()
1. main()
2. initServer() // network 설정 수행
3. serverCron() // 종료, 에러 처리 수행 - Timer 기반, replicationCron() 호출
4. replicationCron() // Master와의 Connection 상태 확인 후 복원 수행, connectionWithMaster() 호출
5. connectionWithMaster()// Replication이 설정된 경우 수행, Master와 실제 연결 시도
5-1. syncWithMaster() // Auth 수행 및 Sync 명령 전달, 임시 RDB 파일 생성
6. readSyncBulkPayload() // Master에게 데이터를 받을 때 수행, sync 완료 후 emptyDB() 호출
7. emptyDb() // 현재 메모리 정리
8. readSyncBulkPayload() // 5-1에서 만든 임시 RDB 파일을 메모리에 로드이러한 Process가 수행되지 않도록 방지하기 위해 Master에 장애가 발생함을 감지하였을 경우, 해당 Master와 Replication을 수행하던 Slave Node를 Master로 승격 시켜 이러한 문제를 방지하는 것이 좋습니다.
- Redis 5.0 미만 버전이라면 SLAVEOF NO ONE을 호출합니다.
- Redis 5.0 이상 버전이라면 REPLICAOF NO ONE을 호출합니다.
Linux kernel에 THP 설정이 적용되어 있는지 확인할 것
THP란 대용량 메모리를 사용하는 Linux에서 관리되는 page의 양이 많아져 CPU가 메모리 요청을 할 때 Lookup 하는 TTB의 크기와 TLB 크기가 커지고 Hit ratio가 줄어들어 것을 메모리 접근에 대한 Overhead가 발생하는 상황을 개선하기 위해 추가된 기능입니다.
기본적으로 제공되는 Page Size가 4K라면 해당 설정이 활성화된 상태에선 2MB 혹은 1GB 크기의 Huge page를 동적 할당하도록 변경되는데, CentOS / RHEL 6 이상 버전에는 기본적으로 적용되어 있다고 합니다.
패치가 되었을지 확인은 못해봤네요
하지만 해당 설정은 Redis 운영에 있어서 치명적인 문제를 일으킬 수 있습니다.
- Redis에서 메모리에 가지고 있는 데이터와 상관없이 큰 사이즈의 Page를 할당하여 Linux Host OOM을 유발할 수 있고 Redis Process의 oom_score 점수를 높일 수 있어 OOM-Killer에게 제거되는 상황이 발생할 수 있습니다.
- 또한 Fork system call의 지연 시간을 증가시키고 앞서 서술했던 COW 문제를 심화시킬 수 있습니다. Persistence 설정으로 인해 BGSAVE 등이 호출되어 Process Memory를 fork 한다면 대량의 메모리를 2개의 child process가 참조하게 되어 이를 작업하는 시간이 오래 걸리고, 활발한 쓰기 요청을 처리하고 있는 Master Node라면 빈번한 메모리의 재할당 / 참조가 발생하여 정말 큰 메모리 공간을 점유할 수 있습니다. (Node max memory + 1GB[최대 페이지 크기]) x 2
해당 설정이 활성화 되었는지에 대한 여부는
// 활성화 시 [always], 비 활성화 시 [never]
/sys/kernel/mm/transparent_hugepage/enabled파일 정보를 통해 확인할 수 있습니다.
해당 내용을 찾아보면서 THP의 이점을 누리려면 Redis 시작 시 최초 메모리 할당 이후에 재 할당이 일어나지 않아야 될 것같다고 생각이 들었는데 그것이 어떤 상황일지 궁금했습니다. 고정된 인원에 대한 리더보드를 관리하는 Redis나 Hyperloglog 등을 사용해 집계를 수행하고 일정 주기로 데이터를 삭제하는 느낌일 것 같은데, 실제로 사용하고 계신 분이 있다면 댓글로 남겨주시길 부탁드립니다! ㅎㅎ
참고 자료
- https://redis.io/topics/persistence
- http://www.yes24.com/Product/Goods/12465544
- university.redis.com (RU301 Running Redis at Scale)
'Programming' 카테고리의 다른 글
| 소소한 글 : Spring4Shell? 이건 또 뭔지... (0) | 2022.03.31 |
|---|---|
| 소소한 글 - Java Version 별 변경 내역 정리하기 (9~18) (0) | 2022.03.24 |
| DevOps : CI / CD의 기본적인 개념 정리 (0) | 2022.02.13 |
| High Availability : 기본적인 복제 개념과 구현 및 동기화 방식 (1) | 2022.02.01 |
| High Availability : 기본적인 장애 감지 알고리즘의 속성과 종류 (0) | 2022.02.01 |