
티스토리 뷰
Logging?
서비스 동작 시 시스템 상태, 작동 정보를 시간의 경과에 따라 기록하는 것을 말한다.
로깅을 사용하는 이유?
서비스 동작 상태를 파악하고, 발생한 장애를 알려주거나, 파악하기 위해 사용한다. 그러기 위해서는 Log Message에 Context를 담아주어야 한다.
어떤 위치에서 어떤 Param을 사용하였고 어떤 것이 실패하였다는 느낌으로 작성하자.
로깅을 사용할 때 주의할 점?
- Log 파일 / DB 생명 주기 & 저장소 용량
- 개인 정보
- 시스템 주요 정보 (시스템 보안, 계정 정보)
Logging을 사용하는 방법?
- Linux System API(sysout)
- Java API(sysout)
- Java API(util.Logging)
- Logging Framework
Spring Boot에서 제공하는 Logging Framework?
- 기본적으로 내부 로깅 동작에 대해서는 common-logging api를 사용한다.
- 별도의 구현체인 Logback, Java API(util.Logging) 등을 활용할 수 있다.
- boot stater의 logging 의존성을 제외함으로써 별도의 Framework를 적용 가능하다.
Slf4j Library?
Slf4j는 여러 Logging Framework를 하나의 통일된 방식으로 사용하게끔 지원하는 추상 API이다.
- Spring Boot Module이 제공하는 AutoConfiguration과 의존성을 그대로 사용할 경우 실제 Binding되는 Module은 Logback이다.
Slf4j Module Structure

API Module
- slf4j의 Logging Interface Module이다.
- 해당 모듈은 추상화된 인터페이스만을 제공하여 Binding될 다양한 로깅 프레임워크를 실행, 배포 시에 선택적으로 주입하도록 지원한다. 이를 통해 추상화 수준을 높이고 일관적인 사용이 가능해진다.
Bridge Module
- 기존에 개발된 레거시 코드를 위해 사용하는 Module이다.
- 기존에 작성된 로거 호출을 가로채 slf4j API로 전달하고 Binding Module과 연결된 Logger를 작동시킨다.
- 여러 개의 Bridge Module 들을 가질 수 있다.
- Binding Library와 같이 사용해서는 안된다.
Binding Module
- 여러가지 Logger Framework 를 일관성 있는 API Module의 Interface와 연결해주는 역할을 한다.
- API Interface가 호출하는 Logger API는 Binding을 통해 연결된 실제 Logger Framework이다.
- Logback, Log4j (v 1.x, 2.x) 등
이것을 사용함으로써
- Facade Pattern을 이용하여 구현부를 숨기고 추상화된 인터페이스를 제공한다.
- 다른 Logging 구현체를 사용하더라도 Application Code가 변경되지 않는다.
- 이를 통해 Application 배포 시에는 원하는 Library로 변경할 수 있게끔 한다.
- 개발 시에는 logback을 사용한다면, 최종 배포 등에는 Log4j2 를 사용하는 등
Slf4j Logging Level
| Logging Level | Description |
| FATAL | Application이 종료될 정도의 심각한 에러를 의미한다. |
| ERROR | 에러가 발생하였으나, Application이 종료될 정도는 아님을 의미한다. |
| WARN | 에러가 될 수 있는 잠재적 가능성이 존재함을 의미한다. |
| INFO | Application의 상태를 간단하게 확인할 때 사용한다. |
| DEBUG | INFO Level보다 더 자세한 정보가 필요한 경우 사용한다. |
| TRACE | DEBUG보다 더 자세한 정보를 제공하며, 개발 환경에서 버그를 해결하기 위해 사용한다. |
- FATAL
- 에러로 인한 비정상 종료 시에 사용되는데, 해당 상황에서는 Log가 남지 않을 수 있음을 고려하여야 한다. (상대적으로 많이 사용되지는 않는다.)
- ERROR
- FATAL, ERROR Level은 의도하지 않은 Exception 정보를 파악하는 데 사용한다.
- 외부 API 호출 시 ERROR가 반환된다거나, 시스템 내부 에러가 발생하였을 때 사용한다.
- WARN
- 인메모리 캐시, DB 커넥션 같은 Resource 가 소진되어갈 때 해당 Level을 통해 정보를 수집하여, 알림을 받아 해결하거나 에러 발생 시 이유를 파악하는 용도로 사용한다.
- INFO
- 명확한 의도를 가지는 Exception 정보를 Logging 하는 데 사용한다.
- Application의 Service Flow가 정상 동작하는지 확인하는 수준의 간단한 Level이다.
- DEBUG
- 권한이 없어 디버깅을 진행할 수 없을 경우, 필요한 level이다.
Logback?
log4j의 여러 문제점을 개선한 Logging Framework이며, 개념적으로 매우 유사하다. ( 이는 동일한 개발자가 프로젝트를 리드하였기에 그렇다고 한다. )
Logback vs Log4j
Logback은 Log4j에 비하여
- 더 빠른 구현 = Logging이 빠르게 수행되며, 메모리 공간을 상대적으로 적게 사용한다.
- 상대적으로 견고하고 신뢰성 있는 내부 테스트들을 수행한다. (테스트 케이스 ^)
- 다른 Logging Library 전환 시에 관련된 작업을 최대한 줄일 수 있다.
- 구성 파일 수정 시 자동으로 해당 내용들을 적용시킨다.
- I/O 장애로부터 원활한 복구가 가능하다.
- Logging을 다시 시작하기 위해 Application 재구동이 필요 없다.
- Log File의 용량, 기간 등을 설정 값을 통해 관리 가능하다.
- Log File에 대한 비동기 방식의 자동 압축을 지원한다.
- 구성 파일에서 조건 식을 이용한 분기 처리가 가능하다.
- 많은 필터 기능을 제공한다.
- Servlet Container와 통합 됨으로써 HTTP-Access Log 기능을 제공한다.
등을 추가하고 개선하였다.
Logback Module Structure

core
- classic, access Module의 기반이 되는 Module이다.
classic
- core를 확장하는 Module 로써 log4 j의 기존 기능을 개선하여 구현하였다.
- 기본적으로 slf4j API를 이용함으로써 log4j, jul, jcl 와 같은 여러 로깅 Framework들과 쉽게 전환을 할 수 있다.
access
- Tomcat, Jetty와 같은 Servlet Container와 통합되어 HTTP-Access Log 기능을 제공한다.
- classic Module과는 독립적으로 구성되며, Container 수준에서 설치되어 사용돼야 한다.
Logback Architecture
Logger, Appender, Layout Interface들이 모여서 Logback Architecture를 구성한다.
Logger
- Application이 Log Message를 생성하는 역할을 수행한다.
- Logger에는 Log Level이 지정될 수 있다.
- Logger의 Level이 지정되지 않는다면 가장 가까운 조상(상위 노드)에게 상속받는다.
- 최상위 Root Logger는 기본 값으로 DEBUG Level이 지정되어 있다.
- log 요청은 Level을 기준으로 같거나 상위 Level 일 때 활성화된다.
- TRACE < DEBUG < INFO < WARN < ERROR
- Package 단위로도 Logging Level을 지정할 수 있으며, 중복적으로 선언될 경우 최하위 Level이 적용된다.
Logger Context
- 각 Logger는 로거 계층 구조에 각각의 Logger를 배치하는 logger Context와 연결된다.
- 계층에 존재하는 모든 로거들은 LoggerFactory의 getLogger를 통해 가져올 수 있다.
// 최상위 Logger // getLogger의 인자는 가져올 Logger의 이름이다. Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER+NAME);- 이때 가져오는 Logger들은 싱글톤처럼 Application에서 하나만 존재하며 여러 Ref Variable은 같은 위치를 참조하게 된다.
Logger는 classic Module의 일부이다. 즉 해당 Module에서만 사용되는 개념이다.
Appender
- 생성된 Log Message를 저장(출력)하는 역할을 수행한다.
- Logger에 2개 이상의 Appender가 존재 가능하다.
- Console Appender
- File Appender
- External Socket Server Appender
- RDBMS Appender
- JMS Appender
- UNIX Syslog Daemon Appender
- addAppender를 통해 주어진 Logger에 Appender를 추가할 수 있다.
- 상위 계층 Logger에서 정의된 Appender는 하위 Logger에도 적용된다.해당 부분을 비활성화하기 위해서는 additivity flag를 false로 설정하여야 한다.
- 이는 요청이 하위 계층에서 상위 계층으로 올라가기에 발생한다.
Layout
- 출력할 Log Message 형식을 지정하는 역할을 수행한다.
- Logback은 기본적으로 PatterLayout을 제공하며 이것을 통해 printf()와 유사한 형식을 사용할 수 있다.
Appender와 Layout은 core Module의 일부이다.
Logger Configuration
Logback의 환경 구성은 일반적으로 Application 초기화 시에 수행된다고 한다.
- 선호되는 방식은 Configuration File을 읽는 것이다.
Log4j2 vs Logback
Log4j2 는 Logback 를 사용하는 것에 대해 여러 이점이 있다고 한다.

- 멀티 스레드 환경에서의 Logging 성능 차이 (최대 처리량)
- 이는 Log4j2의 Logger가 낙관적 락을 사용하여 구현되는 반면에 Logback에서는 ArrayBlockingQueue를 사용하기 때문이다.
- Appender 관련해 Queue에 Log Event를 추가할 때 잠금 경합이 발생하기도 한다.
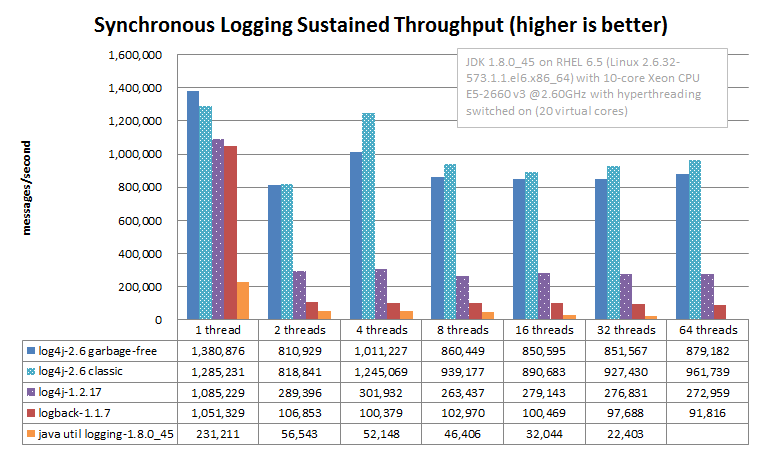
- (동기성) 파일 Logging 지속 처리량
- 모든 시스템에서 최대 지속 처리량은 가장 느린 구성요소에 의해 결정된다.
- Logger에서는 Appender의 Massage Format, Disk I/O를 의미한다.

- 비동기 Logging 시 Parameterized Message Formating
- 멀티 스레드 환경에서 성능 차이가 많이 벌어지지만(높지만), 매개 변수 수에 따라서 Formating 비용이 급격히 증가한다고 한다.
간단하게 살펴보니 Log4j2는 대부분의 상황에서, 특히 멀티 스레드 환경에서 성능의 이점이 큰 것을 알 수 있다.
하지만 왜 Log4j2를 Spring Boot의 기본 Logger로 사용하지 않을까?
내용 출처 : https://github.com/spring-projects/spring-boot/issues/16864
Log4j2 의 성능이 멀티 스레드 환경에서 우세함을 보이지만 이것이 개발자들에 있어 일반적으로 선택할만한 이유가 되지는 않는다고 생각한다.
- 잘 추상화된 Interface와 Spring Boot 설정을 통해 쉽게 Logger 구현체를 변경 가능함으로 필요한 경우에 log4j2를 사용하면 된다.
- 이것을 기본 Logger로 등록하게 된다면, 기존에 Logback을 사용하던 프로젝트들이 변경(마이그레이션)하는데 큰 어려움을 주게 된다. (Boot 1.X → 2.X ...)
이러한 내용들을 통해 성능만이 어떤 기술을 도입하고, 변경하는데 의미를 주지 않는다는 것을 알게 되었다. 특히나 Application에서 제일 비중 있는 DB (Query 성능 등)이 아닌 이상에는 더욱 그런 느낌을 받게 된다.
System.out.println() vs Logger
로그 출력, 저장 방식
Logger
- Logger는 Log 내역을 별도의 파일에 저장할 수 있다.
- Logger는 Layout 을 이용해 메시지에 대한 일관적인 형식을 지정할 수 있다.
- Log의 유지 기간, 파일 용량 등을 설정하여 자동화된 관리를 제공한다. Framework 지원 여부
- Log를 압축하여 관리할 수 있다. Framework 지원 여부
- Log를 출력하는 데 있어서 기본적인 설정이 필요하고 인스턴스 사용을 해야 한다.
- 다양한 저장 방식을 제공하고 일관적인 형식 지정이 가능하며, 자동화된 관리 방식을 제공한다.
System.out.println()
- println()은 Log를 콘솔에만 출력할 수 있다.
- 설정하지 않아도 메서드 하나로 로그를 출력할 수 있다.
- 상황에 따라 필요하지 않은 log들도 Console에 모두 출력된다.
- 각각의 Println() 마다 출력 형식을 지정하여야 한다.
- 당시 날짜, 시간을 출력하지 않는 한 언제 발생한 로그인지 확인조차 어렵다.
- 형식을 지정하는데 상대적으로 많은 노력이 필요하며, 저장이 되지 않는다.
로그 분류, 제어
Logger
- Logger는 Log 내역을 별도의 파일, 서버, DB 등에 저장할 수 있다. (Appender)
- Logging 레벨을 통해 log 정보들을 분리할 수 있다.
- Logging 래벨 설정을 통해 필요한 log만 출력할 수 있다.
- 로그를 세분화하여 관리할 수 있고 필요한 데이터만을 모니터링할 수 있다.
System.out.println()
- 출력되는 메시지를 제어할 수 없다.
- Application env (Was)의 로그와 섞여서 출력된다.
- 로그가 남지 않으며, 제어를 할 수 없고 상황에 따라 정확한 모니터링이 불가능하다.
사용하는 리소스 량, 동기화 문제
Logger
- Logger Framework는 일반적으로 Blocking Queue나 낙관적 락이 적용된 자료구조를 통해 Log를 저장하며, 별도의 출력이 없는 경우에 기록을 진행한다.
- 서버의 실시간 처리량에 최대한 영향을 미치지 않는다.
- FIFO 자료구조로 Log가 삽입되기 때문에 로그를 순차적으로 저장할 수 있다.
System.out.println()
- println()은 매 실행시마다 스트림을 생성하고 I/O 작업(System.call)을 진행하는 Blocking 방식이다. 이는 로컬 개발 PC에서는 큰 성능 차이와 리소스 문제를 나타내지 않을 수 있지만, 실제 운영 중인 서버에서는 큰 차이가 발생하게 된다.
- 서버의 실시간 처리량에 큰 영향을 미친다.
- 로그가 순차적으로 저장되지 않기에 별도의 동기화 코드를 구현하여 사용하여야 한다.
- 멀티 스레드에 안전하게 구현되지 않았다.
- 요청 처리에 따라 로그가 소실될 수 있다.
System.out.println() vs Logger 결론
위에서 다룬 모든 경우 (간편한 사용 방식을 제외한)에서 Logger가 Println() 보다 우세함을 알 수 있다. 요즘 개발을 공부하고, 여러 자료를 찾아보면서 느끼는 SW의 중요 요소는 유지보수라는 것이다.
결국 Logger를 사용하는 것도 그러한 이유를 위해서라고 생각한다. 개발만이 그 SW의 전부가 아니기에, 사실상 운영하고 유지보수되는 기간이 더욱더 길 것은 자명하기 때문에 더 중요하게 생각하는 것은 아닐까?
[ 추가된 내용 ]
- 2021-12-09일 쯤 공유되었던 Log4j 2.x 취약점은 2.0.0 에 추가된 JNDI Lookup 기능 때문이다.
- 해당 취약점은 2.15.0 버전에서 해결하였으나 미흡한(?) 처리로 인해 DDOS 공격이 가능한 상태가 되어 다시 패치한 2.16.0 버전에서 해결 되었다.
- 1.x 버전의 경우 JMSAppender를 사용하지 않아야 안전하다.
- 2021-12-15일 쯤 공유되었던 Logback 1.2.9 이전 버전의 취약점은 그보다 치명적인 취약점은 아니나, JNDI Lookup과 관련된 취약점임은 동일하다.
- 해당 취약점을 이용하기 위해선 3가지의 조건을 만족하여야 하는데 이게 가능한 수준이면 이미 서버가 털린 상태나 다름없지 않나 싶다.
- 1. 공격자가 서버에 접속하여 Logback config 파일에 쓰기 권한을 가질 것
- 2. 공격자가 쓰기 권한을 이용해 config 파일을 변조한(Scan = true) 다음 Application을 재기동 시킬 것
- 3. 1.2.9 버전 밑의 Logback을 사용하고 있을 것
- 해당 취약점을 이용하기 위해선 3가지의 조건을 만족하여야 하는데 이게 가능한 수준이면 이미 서버가 털린 상태나 다름없지 않나 싶다.
출처
- https://javarevisited.blogspot.com/2016/06/why-use-log4j-logging-vs.html
- https://www.baeldung.com/java-system-out-println-vs-loggers
- https://stackoverflow.com/questions/2746578/advantage-of-log4j
- http://logback.qos.ch/reasonsToSwitch.html
- http://www.slf4j.org/legacy.html
- https://logging.apache.org/log4j/2.x/performance.html
'Programming' 카테고리의 다른 글
| Spring Auto-Configuration Condition Annotations (0) | 2021.01.12 |
|---|---|
| Spring Boot의 Auto Configuration! (0) | 2021.01.12 |
| Java Database Connectivity 알아보기! (0) | 2021.01.01 |
| Java에서 구현할 수 있는 Proxy들 (Pure, JDK, CGLIB) (0) | 2020.12.27 |
| RestTemplate, Traverson, WebClient 정리하기 (0) | 2020.12.25 |
- Total
- Today
- Yesterday
- mybatis
- JDK Dynamic Proxy
- java
- 회고
- 커뮤니티 오거나이저
- URI
- RESTful
- 게으른개발자컨퍼런스
- cglib
- 2025년 회고
- Redis Key
- lambda
- WiredTiger
- URN
- RPC
- JVM
- configuration
- 한국 스프링 사용자 모임
- Optimistic Locking
- spring
- transaction
- 근황
- rabbitmq
- Url
- spring AOP
- AMQP
- JPA
- Request Collapsing
- HTTP
- Switch
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |