
티스토리 뷰
이 글은 특정 구현에 종속되는 내용을 제외한 이론 위주의 정리 글입니다.
Sharding이 필요한 이유?
서비스의 특성이나 운영되어온 기간에 따라 사용자의 Data, State는 지속적으로 축적되게 됩니다. 이러한 것들이 몇 천만에서 수십 억 또는 그 이상으로 늘어난다면, Index와 같은 요소를 잘 구성되어 있더라도 결국 조회 성능의 하락이나 Data, State를 관리하는 Node에게 큰 부하를 주게 됩니다.
이는 결국 서비스의 지연 발생 빈도 수나 기간이 늘어나는 주요한 원인 중 하나가 됩니다.
이를 대비하기 위해 우리는 Performance와 Scalability 속성을 만족하는 서비스 설계를 진행하여야만 합니다. 그리고 이 속성을 지원하는 설계 방법 중 하나로는 Sharding 구조가 있습니다.
Sharding?
Sharding이란 기본적으로 특정 Attribute(Shard key)를 기준으로 하나의 DataSet을 여러 Shard Node에 분산하여 작은 단위의 DataSet으로 나누고 관리하는 것을 의미합니다.
Sharding은 일반적으로 Horizontal Partitioning과 혼용되는 용어입니다. 명확하게 따지자면, horizontal partitioning은 하나의 Node 안에서 DataSet을 여러 DataSet으로 나누는 것이고, Sharding은 DataSet을 여러 Node에 나누는 것입니다.
저는 이 글에서 Sharding, Horizontal Partitioning을 모두 “Sharding”이라고 서술하겠습니다.
이를 통해 우리는 서비스가 관리하는 Data, State에 접근하는 트래픽을 분산하여 관리하고 있는 Shard Node들의 처리 성능과 서비스의 동시 처리량을 향상시킬 수 있습니다. 또한 각 Shard Node의 장애는 격리되어 다른 Shard Node에 전파되지 않기 때문에 서비스의 High Availability를 향상시킵니다.
이러한 특징으로 인해서 Sharding은 “High Availability : 기본적인 복제 개념과 구현 및 동기화 방식” 에서 언급한 Query Off Loading 구조의 한계를 보완할 수 있습니다.
Replication을 활용한 Query Off Loading 구조를 사용하는 경우 Origin의 Read Query 부하는 분산 가능하나, Write Query에 대한 부하는 분산할 수 없습니다. 즉 Write Query 부하가 가중될수록 Replica Node의 수와 상관없이 Read, Write Query 처리 성능이 하락한다는 것입니다. - Write Heavy Situation
이러한 문제가 발생하는 이유는 Replica Node들 또한 Origin Node가 처리한 Write Query의 Log를 별도의 스레드로 처리하여 Node가 관리하는 상태에 반영하는 구조이기 때문입니다.
이때 Sharding을 도입한다면 하나의 Origin Node가 받던 요청을 여러 Origin Node로 분산시키기 때문에 해당 구조의 한계를 보완할 수 있습니다.
하지만 Sharding이 장점만 가지고 있는 전략은 아닙니다.
- 시스템 구조의 복잡성이 늘어나는 점 (특히나 직접 구현해야 하는 경우)
- Sharding 되고 있는 Shard Node 들에 대한 불균형 문제를 고려해야 하는 점
- Shard Node 추가 및 Rebalancing 작업 등 운영 관리 비용의 증가
- 다른 Node에 분산된 DataSet 간의 Join, Compose가 어려운 점
이러한 문제점도 많기 때문에 사용할 Sharding 전략과 운영 전략을 잘 세우고 구현해야 합니다.
Sharding은 Redis, MongoDB Cluster, MySQL NDB Cluster, Elasticsearch나 Solr와 같은 여러 Solution 및 Opensource에서 활용되고 있으며 많은 서비스에서 상황에 따라 Code Level의 Sharding 기법을 구현하고 있습니다.
Sharding 구현 방식?
Sharding 구현 방식으로는 크게 Range, Moduler, Directory, Index Sharding 등이 있습니다.

Range Sharding은 Shard Key로 선정된 Attribute의 일정 범위를 관리할 DataSet을 결정하는 것으로 Rebalancing 없이도 쉽게 새로운 Shard Node를 추가할 수 있습니다. 하지만 Shard Node 간에 DataSet Size가 균등하지 않는 문제가 발생할 수 있습니다. - Hotspot problem
결국 Hotspot problem 문제로 인해 기존 Shard Node를 분할하여 Rebalancing 하는 작업이 필요하고, 반대로 들어오는 요청이 적거나 DataSet이 작은 Shard Node는 Integration 또는 Migration 작업을 통해 운영 비용을 최적화해야 하는 어려움이 존재합니다.
- 이를 보완하는 방법으로는 MongoDB에서 사용하는 Chunk 단위 분할 방식이 있으며, 해당 방식은 Shard key에 대해 특정 범위를 결정하고 그 범위를 넘어설 때마다 새로운 Chunk를 생성하여 Data를 Migration 하는 방식입니다.

Moduler Sharding(Hash Sharding)은 Key로 선정된 값을 현재 존재하는 DB Node 개수로 나누어서 결과 값을 기준으로 저장될 Node를 결정하는 방식입니다. 이 방식은 Range Sharding에 비해서 DataSet을 균등하게 분배할 수 있으나 다른 Shard Node를 추가하였을 때 기존 DataSet를 Rebalancing 하는 것이 어렵습니다.
- User ID, Client IP, Post number 같은 값을 Hash Function이나 Moduler 연산을 통해 Shard Key로 변환하여 Shard Node를 결정합니다.
Data를 일관적으로 분산하기 위해서는 당연히 Hash Function에 넘겨지는 값을 동일한 Attribute열에서 제공해야 하며, 이 값은 변경되지 않는 정적 값이어야 합니다.
해당 방식의 Rebalancing 비용을 줄이기 위해서 Scale-out 시 2개의 배수로 Shard Node를 추가하는 전략(이를 통해 데이터가 전달될 영역을 특정할 수 있습니다.)과 최대로 늘어날 수 있는 한계 값을 미리 정해 놓고 해당 값을 초과할 시점부터는 Scale-up을 진행하는 전략을 고려하기도 합니다.
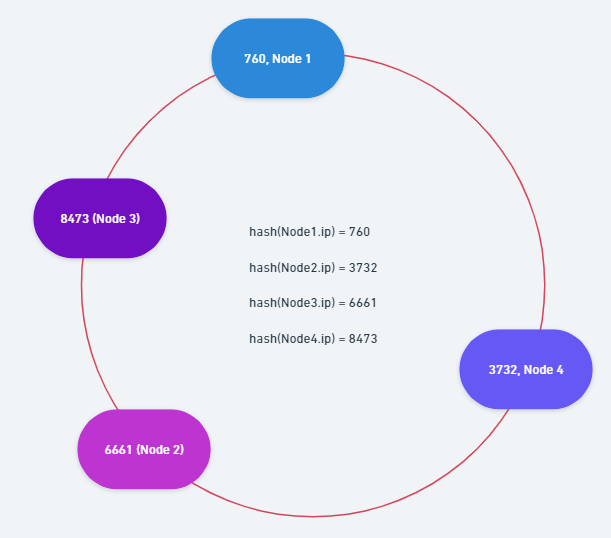
Consistent Hashing은 Moduler(Hash) Sharding와 같이 Hash Function을 사용하지만 상대적으로 Rebalancing 시에 다른 Shard Node로 분산되는 Data를 최소화할 수 있는 방식입니다.
기본적으로 환형 큐와 같은 자료 구조(논리적인 구조)에 배포되어 있는 Shard Node의 IP를 Hash하여 자료구조의 Index로 변환하고 Query 요청을 하는 사용자 또는 Client의 IP를 Hash 하여 나온 값과 제일 인접한 Shard Node에 저장하는 식으로 Sharding 규칙을 지정하여 Data를 분산시킬 수 있습니다.

새로운 노드가 추가되었을 때에는 앞선 상황과 마찬가지로 해당 Shard Node의 IP를 Hash하여 Index를 지정하고, 나온 Index 값보다 낮은 값을 가진 인접 Shard Node와 자신 사이에 속하는 Data만 Rebalancing을 진행합니다.
- 해당 사진에서는 761 ~ 1332 안에 속하는 Shard Key를 가진 Node 4의 Data가 새로 추가된 Shard Node5로 Migration 됩니다.
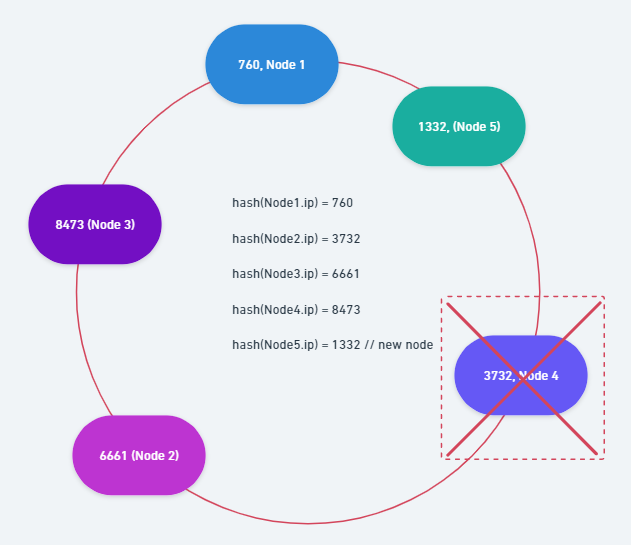
하지만 해당 방식을 사용하면 Hash 된 값에 따라 특정 Shard Node(Node 2)에게 넓은 범위가 할당되어 많은 양의 Data가 전달되는 불균등 문제가 발생할 수 있으며, 인접한 Shard Node가 장애 발생이나 부하에 의한 처리 지연으로 정상적인 상태가 아닌 것으로 판단되었을 때 인접한 다음 Shard Node에게 부하를 가중시킬 수 있습니다.
- 해당 사진에서는 Shard Node 4의 장애 발생으로 1333 ~ 6661 안에 속하는 모든 Data가 Shard Node 2로 분산됩니다.

해당 문제를 방지하기 위해서, (그리고 Rebalancing 단위를 좀 더 최소화 하기 위해서) 기존 Shard Node의 ip에 특정 값을 추가하여 Hash 한 후 이를 Virtual Shard Node로 추가하여 Shard Node마다 관리하는 Shard Key, Data의 수를 조절할 수도 있습니다.
- 해당 방식을 정리하자면 Consistant Sharding 방식은 Hash Function 을 사용하면서도 Rebalancing 작업 시 이동해야 할 Data를 최소화할 수 있으며, 성능 및 상황에 따라 Shard Node의 부하를 조절할 수 있습니다.
- 하지만 Shard Node 간의 Data 분산이 균등하지 않은 문제나 인접 Shard Node의 장애에 따른 부하 가중 문제가 발생할 수 있으며, 이를 최소화하기 위해 Virtual Shard Node를 추가할 수 있습니다.
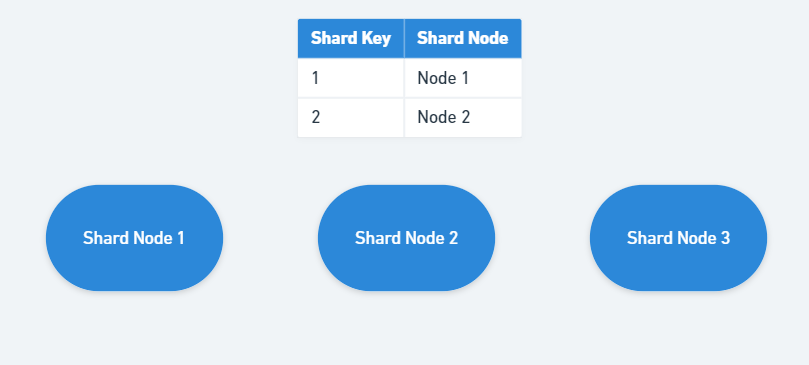
Directory Sharding은 Shard Key를 기준으로 어떤 Shard Node가 DataSet를 보유하고 있는지 확인할 수 있는 Static Lookup Table을 만들고 유지하는 방식입니다. 특정 Shard Key로 저장된 DataSet 위치를 지속적으로 기록합니다.
Range Sharding이나 Moduler Sharding과 비교하여 유연한 방식이지만, 해당 방식을 사용하면 모든 Read 또는 Write Query 처리 이전에 먼저 Static Lookup Table에 접근해야 하기 때문에 전체적인 처리 성능을 저하시킬 수 있습니다.
- Range Sharding은 Shard Key에 대한 범위를 지정해야 한다는 점, Moduler Sharding의 경우 Hash Function 또는 Moduler 로직을 구현해서 사용해야 합니다.

Index Sharding(또는 Dynamic Sharding)은 Directory Sharding 방식과 유사하나 Shard Key와 Node를 관리하는 주체를 Table이 아니라 외부 Index 서비스(또는 Locator 서비스)로 제공하는 방법으로 저장할 위치를 알고 있는 서비스를 이용하여 정보를 요청한 Client에게 Lookup Key 또는 Shard node 위치를 알려주는 방식입니다.
이러한 Index 서비스에는 Admin 기능을 제공하여 불균형을 감지한 경우에 DataSet의 특정 값들을 다른 Shard Node로 안전하게 Migration 할 수 있도록 Index 서비스에 요청을 하면 Index 서비스는 Write 요청을 거부하고 Read Query만 허용하는 식으로 안전장치를 마련할 수 있습니다.
- 하지만 해당 방식을 사용하면 Index 서비스를 따로 구축해야 하는 점, 운영 비용, SPoF가 될 수 있다는 점을 고려하여 상대적으로 복잡한 설계 및 개발이 필요합니다.
- Index 서비스의 장애 상황 발생 시 전체 서비스의 요청 실패 문제를 완화하기 위해 Index 서비스에 대한 요청이 성공한 경우 Shard Node와 관련된 값을 Local Cache에 저장하고 이후 요청에는 이를 활용하도록 개선할 수도 있습니다. (Index 서비스에 대한 트래픽 완화)
참고 자료
- https://en.wikipedia.org/wiki/Shard_(database_architecture)
- https://woowabros.github.io/experience/2020/07/06/db-sharding.html
- Mastering the System Design Interview
- The RED : 백엔드 에센셜 : 대용량 서비스를 위한 아키텍처 with Redis by 강대명
- NoSQL 철저입문
'Programming' 카테고리의 다른 글
| Performance : 기본적인 Application Cache 개념과 종류 (0) | 2022.06.25 |
|---|---|
| 소소한 글 : Spring Vesion 별 변경 내역 정리하기 (2.1.x ~ 2.5.x. WIP) (0) | 2022.04.11 |
| 소소한 글 : Spring4Shell? 이건 또 뭔지... (0) | 2022.03.31 |
| 소소한 글 - Java Version 별 변경 내역 정리하기 (9~18) (0) | 2022.03.24 |
| Redis : Data Persistence (0) | 2022.02.14 |
- Total
- Today
- Yesterday
- HTTP
- spring
- RPC
- mybatis
- JPA
- transaction
- AMQP
- spring AOP
- java
- RESTful
- 커뮤니티 오거나이저
- Redis Key
- configuration
- Url
- rabbitmq
- 한국 스프링 사용자 모임
- cglib
- 게으른개발자컨퍼런스
- JVM
- WiredTiger
- lambda
- Request Collapsing
- URI
- 2025년 회고
- Optimistic Locking
- 회고
- JDK Dynamic Proxy
- 근황
- Switch
- URN
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |