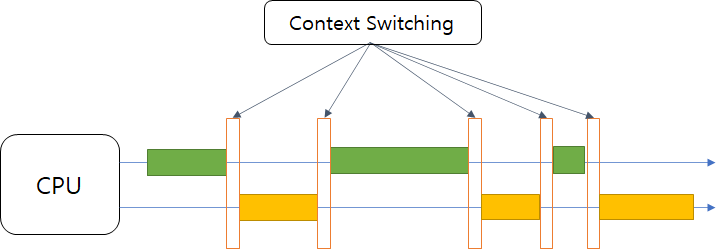
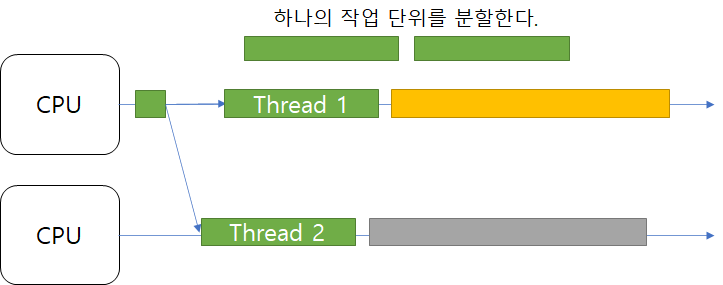
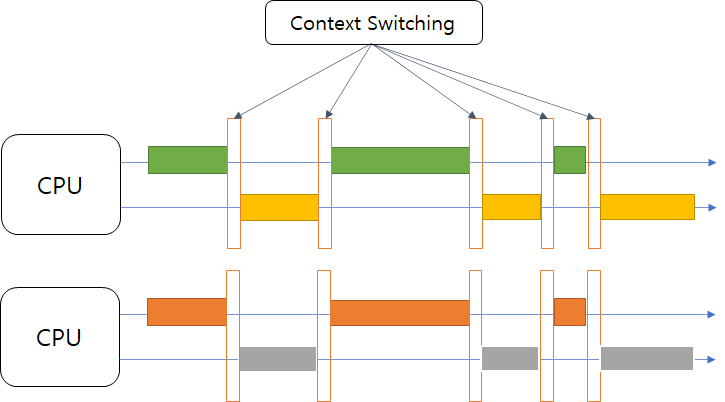
서비스 메서드에 Transcational을 사용하였을 때와 사용하지 않았을 때, 흐름을 정리해보았습니다.
스프링 @Transaction 미적용 (JDBC API - Local Transaction)
기본적으로 JDBC의 트랜잭션은 하나의 Connection Instance를 생성하고 통신하며 종료하는 흐름과 같이 동작하게 된다.
즉 코드에 존재하는 DAO 로직들은 각각의 트랜잭션 안에서 연산을 진행하게 되는 것이다.
이때의 트랜잭션을 로컬 트랜잭션이라고 한다.
해당 메서드 내에서는 3개의 트랜잭션이 동작하며, 이는 내부에서 하나의 DAO 로직이 실패하더라도 다른 로직들은 성공하고 반영될 수 있는 상태임을 의미한다.
각각의 로직들은 Connection Pool에서 리소스 전달받아 새로운 Connection을 생성하며, Auto-Commit을 진행한다.
트랜잭션을 적용했다면?
단순하게 생각해본다면, 여러 질의를 포함하는 트랜잭션을 구성하기 위해서 하나의 커넥션을 생성하고 Auto-commit을 false 처리한 뒤 이 커넥션을 재사용을 하면 될 것 같다.
Spring에서는 이를 구현하는 방법을 Transaction Synchronization이라고 한다.
Transaction Synchronization?
개념 정립을 위하여 만든 이미지이므로 실제 내용과는 다를 수 있습니다.
트랜잭션을 시작하기 위해 사용할 Connection 객체를 저장소 역할을 하는 Connection Holder에 보관하고, 이후 호출 로직들에 대해서 매번 Connection을 생성하고 사용하는 것이 아니라 해당 Connection만을 꺼내어 재사용하게끔 한다.
트랜잭션 동기화를 적용한 JDBC Template work flow
DAO의 호출을 위한 connection을 트랜잭션 경계 상단에서 생성한다.
해당 connection 객체를 TransactionSynchornizationManager 내부의 참조 변수인 connectionHolder 객체에 저장한다.
connection의 Auto-commit 설정 값을 false로 설정한다.
DAO의 메서드가 호출되면 우선 Manager 내부의 Holder 객체에 connection이 있는지 확인한다.
저장되어 있는 Connection을 가져오고 Statement 객체를 생성하여 쿼리를 전송한다. 그리고 연산 종료 시 해당 connection을 종료시키지 않고 열어둔다
위와 같은 연산을 진행하며 Runtime Exception이 발생하면 connection 객체의 RollBack을 실행하고 그렇지 않은 경우 commit을 실행한다.
Spring Transcation Synchronization Interface
TransactionSynchronizationManager
스프링에서 제공하는 Transaction Synchronization 용 Manager Class이다.
선언적 트랜잭션을 이용하게 될 경우 트랜잭션 경계의 맨 첫 부분에서 initSynchronization()를 호출하여 트랜잭션 동기화 작업을 진행한다.
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations =
new NamedThreadLocal<>("Transaction synchronizations");
/**
* Return if transaction synchronization is active for the current thread.
* Can be called before register to avoid unnecessary instance creation.
* @see #registerSynchronization
*/
public static boolean isSynchronizationActive() {
return (synchronizations.get() != null);
}
/**
* Activate transaction synchronization for the current thread.
* Called by a transaction manager on transaction begin.
* @throws IllegalStateException if synchronization is already active
*/
public static void initSynchronization() throws IllegalStateException {
if (isSynchronizationActive()) {
throw new IllegalStateException("Cannot activate transaction synchronization - already active");
}
logger.trace("Initializing transaction synchronization");
synchronizations.set(new LinkedHashSet<>());
}
해당 작업은 해당 스레드 내부에서만 사용될 값을 저장하는 ThreadLocal 객체에 LinkedHashset 컬랙션 객체를 저장하고, 이 안에는 트랜잭션 동기화 설정과 관련된 필드를 가지는 TransactionSynchronization 타입의 객체를 저장한다.
내용 추가 : resultType을 entity, dto 등의 Value Object으로 지정할 경우 resultMap을 생성한다.
마이바티스와 롬복을 같이 사용하는 것은 처음이다보니 사소한 실수를 통해 여러 예외를 만나게 되는 것 같다.
User 도메인을 개발하기 시작했기에 엔티티를 작성하고 테스트 데이터베이스 스키마와 데이터를 추가한 뒤 MapperTest를 통해 조회 테스트를 진행하던 중 문제가 발생하였다.
Caused by: org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: java.lang.IndexOutOfBoundsException: Index 9 out of bounds for length 9
### The error may exist in file [C:\Users\serrl\Desktop\Mentoring\Somaeja\out\production\resources\mybatis\mapper\user.xml]
### The error may involve com.somaeja.user.mapper.UserMapper.findByAll
### The error occurred while handling results
### SQL: SELECT * FROM USER
### Cause: java.lang.IndexOutOfBoundsException: Index 9 out of bounds for length 9
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:149)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:140)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:426)
... 82 more
Caused by: java.lang.IndexOutOfBoundsException: Index 9 out of bounds for length 9
at java.base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64)
at java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70)
at java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:248)
at java.base/java.util.Objects.checkIndex(Objects.java:372)
at java.base/java.util.ArrayList.get(ArrayList.java:458)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.createUsingConstructor(DefaultResultSetHandler.java:708)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.createByConstructorSignature(DefaultResultSetHandler.java:693)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.createResultObject(DefaultResultSetHandler.java:657)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.createResultObject(DefaultResultSetHandler.java:630)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.getRowValue(DefaultResultSetHandler.java:397)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.handleRowValuesForSimpleResultMap(DefaultResultSetHandler.java:354)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.handleRowValues(DefaultResultSetHandler.java:328)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.handleResultSet(DefaultResultSetHandler.java:301)
at org.apache.ibatis.executor.resultset.DefaultResultSetHandler.handleResultSets(DefaultResultSetHandler.java:194)
at org.apache.ibatis.executor.statement.PreparedStatementHandler.query(PreparedStatementHandler.java:65)
at org.apache.ibatis.executor.statement.RoutingStatementHandler.query(RoutingStatementHandler.java:79)
at org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:63)
at org.apache.ibatis.executor.BaseExecutor.queryFromDatabase(BaseExecutor.java:325)
at org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:156)
at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:109)
at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:89)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:147)
... 88 more
난데없이 IndexOutOfBoundsException가 발생하여 (발생할 꺼리도 없는데????) 약간 헤매긴 하였는데 몇몇 요소를 검증하니 찾을 수 있었다.
문제는 바로 Entity 객체였다. (사실은 내 문제다..!)
@Builder
@Getter
@ToString
public class User {
private final Long id;
private final Long locationId;
private final String nickName;
private final String password;
private final String email;
private final String phoneNumber;
// 계정 권한
private final String role;
private final LocalDateTime createdDate;
private final LocalDateTime modifyDate;
// Inner Join 을 통해 가져오는 데이터
// 이것이 누락되었다..!
private final String cityCountryTown;
}
<select id="findByAll" resultType="com.somaeja.user.entity.User">
SELECT *
FROM USER
</select>
Entity를 별도의 설정자 없이 빌더 패턴으로 생성하다보니 모든 필드 값을 final로 설정하였었는데, 테스트를 작성하기 전에 간단하게 작성했던 xml 에서 Join을 통해 가져올 데이터를 누락시키고 있었기에 해당 Entity 생성 로직 자체가 실패한 것이였다.
<select id="findByAll" resultType="com.somaeja.user.entity.User">
SELECT USER.*, LOCATION.CITY_COUNTRY_TOWN as location
FROM USER INNER JOIN LOCATION
ON USER.LOCATION_ID = LOCATION.LOCATION_ID
</select>
이렇게 변경하여 해당 필드 데이터로 가져옴으로써 해결하게 되었다.
내부 로직을 보지않아 정확히 알 수는 없지만 요소가 빠짐으로써 발생하는 Exception이라면 IndexOutOfBoundsException이 아니라 IligalArgumentException을 사용하는 것이 더 좋지 않았을까 라는 생각이 들었다. (물론 내부 로직에 그럴만한 이유가 있겠지...)
다른 상황?
다른 문제로도 해당 예외가 발생할 수 있는데, 이는 resultType에서 객체를 사용할 때와 resultMap을 사용할 때 나타나는 경우이다.
예시 Entity
@Builder
@Getter
public class Account {
private Long id;
private String name;
private String nickname;
private String phoneNumber;
private Boolean phoneVerified;
}
이러한 resultMap을 정의하고 단순하게 id를 통해 조회하는 SELECT 쿼리를 작성하였다.
이 경우에도
Caused by: org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: java.lang.IndexOutOfBoundsException: Index 5 out of bounds for length 5
### The error may exist in file [mybatis\mapper\account.xml]
### The error may involve ...mapper.AccountMapper.findById
### The error occurred while handling results
### SQL: SELECT * FROM Account WHERE id = #{accountId}
### Cause: java.lang.IndexOutOfBoundsException: Index 5 out of bounds for length 5
이러한 에러가 발생할 것이다. 이는 resultMap의 특성 때문인데, 해당 기능을 사용할 경우 (+resultType 을 사용할 때 객체를 넘겨줄 경우 동일하다.) Mybatis가 미리 해당 인스턴스를 생성하게 된다. 하지만 위의 엔티티는 모든 인자가 포함된 생성자 (Builder) 만이 존재하기 때문에 인스턴스를 생성할 수 없어 문제가 발생하게 되는 것이다.
이 것을 해결하기 위해서는 인자가 없는 생성자를 추가하면 된다.
@Builder
@Getter
@NoArgsConstructor <-- 이것을 추가해주면 된다.
public class Account {
private Long id;
private String name;
private String nickname;
private String phoneNumber;
private Boolean phoneVerified;
}
이렇게 한다면 앞서 언급한 특징에 의해 발생한 문제일 경우 해결될 것이다.
@Builder에 대한 토막글
Finally, applying @Builder to a class is as if you added @AllArgsConstructor(access = AccessLevel.PACKAGE) to the class and applied the @Builder annotation to this all-args-constructor. This only works if you haven't written any explicit constructors yourself.
내부에 정의된 클래스 패스들을 따라가게 되면 @ConditionalXXX를 통해 각각의 조건을 검증하여 통과하는 경우에 등록하는 방식으로 선언되어 있다.
ex) DispatcherServletAutoConfiguration
@AutoConfigureOrder(Ordered.HIGHEST_PRECEDENCE)
@Configuration(proxyBeanMethods = false)
@ConditionalOnWebApplication(type = Type.SERVLET)
@ConditionalOnClass(DispatcherServlet.class)
@AutoConfigureAfter(ServletWebServerFactoryAutoConfiguration.class)
public class DispatcherServletAutoConfiguration {
/**
* The bean name for a DispatcherServlet that will be mapped to the root URL "/".
*/
public static final String DEFAULT_DISPATCHER_SERVLET_BEAN_NAME = "dispatcherServlet";
/**
* The bean name for a ServletRegistrationBean for the DispatcherServlet "/".
*/
public static final String DEFAULT_DISPATCHER_SERVLET_REGISTRATION_BEAN_NAME = "dispatcherServletRegistration";
// DispatcherServletRegistrationConfiguration...
// DefaultDispatcherServletCondition...
// DispatcherServletRegistrationCondition...
}
EnableAutoConfiguration 흐름 요약
Context가 초기화되면 등록된 BeanPostProcessor들을 이용하여 BeanDefinition들을 읽어오게 됩니다. 이때 AutoConAutoConfigurationPackage와 연결된 AutoConfigurationPackage.class의 정적 클래스인 registrar가 Spring.factory파일의 클래스 패스 정보를 통해 Configuration Class들을 모두 가져와 저장하게 되고, 이것이 ConfigurationClassBeanDefinitionReader를 통해서 읽어져 온 뒤 ConfigurationClassParser에서 Condition 구현체를 통한 조건 검증을 진행하고 통과한 Bean Definition에 대해서만 ImportStack에 추가하여 BeanPostProcessor가 해당 정보를 싱글톤 형식의 Bean으로 등록하게 됩니다.
@Configuration
해당 어노테이션이 작성된 클래스가 Java Config 기반의 Bean Definition 으로 사용되는 것임을 나타낸다.
내부적으로 @Component라는 Meta-Annotation이 정의되어 있으므로 ComponentScan을 통해 탐색되어 읽어 들일 수 있으며, 이는
내부의 processConfigBeanDefinitions() 메서드를 호출한 뒤 ConfigurationClassParser 를 통해 읽어 들여진 Configuration Class들을 ConfigurationClass 타입으로 파싱 한다.
해당 정보를 ConfigurationClassBeanDefinitionReader의 loadBeanDefinitions() 메서드에 전달하여 순회한다.
순회되는 정보들을 loadBeanDefinitionsForConfigurationClass() 메서드를 통해 정보를 읽어 들어와 Bean Definition으로 등록한다.
이후 ConfigurationClass 객체들을 alreadyParsed에 저장하고 다음 로직을 진행한다.
의 흐름을 가지고 등록되게 된다.
@EnableAutoConfiguration에 포함된 AutoConfigurationImportSelector.class, @AutoConfigurationPackage의 흐름 따라가 보기
Import(AutoConfigurationImportSelector.class)
META-INF/spring.factories에 존재하는 정보들을 가져와 등록하는 클래스이다.
Main 메서드가 호출되고 run 메서드가 실행된다.
run 메서드 실행 중 refreshContext() 메서드가 ConfigurableApplicationContext 타입의 객체를 전달받으며 호출된다.
넘겨받은 객체 타입을 검증하는 refresh(ApplicationContext) 메서드에 전달하여 확인하고 해당 객체 타입의 인자가 전달되지 않는 refresh() 메서드를 호출한다.
메서드 내부적으로 invokeBeanFactoryPostProcessors(BeanFactory); 를 호출한다. 인자로 전달받은 beanFactory에서 PostProcessor 개수를 전달받은 뒤 순회하면서 해당 정보를 ArrayList인 currentRegistryProcessors에 저장한다.
currentRegistryProcessors를 정렬하고 해당 리스트와 beanFactory를 BeanDefinitionRegistry로 Casting 한 다음 invokeBeanDefinitionRegistryPostProcessors() 메서드에 전달한다.
내부적으로 전달받은 ArrayList를 순회하며 각각의 PostProcessor 들을 등록하는 절차를 진행하는 중 postProcessBeanDefinitionRegistry → processConfigBeanDefinitions에 regisrar 정보를 넘긴다.
processConfigBeanDefinitions 내부에서 BeanDefinitionHolder 정보를 담는 ArrayList인 configCandidates 객체를 생성한 뒤 해당 객체의 요소를 추가하는 작업을 진행한다.
→ 전달받은 registry가 가지고 있는 DefinitionNames 들을 가져와 순회하면서 BeanDefinition 정보와 Bean Name을 꺼내오고 그것을 저장하는 BeanDefinitionHolder를 생성하여 저장한다.
configCandidates 객체를 정렬한 뒤 ConfigurationClassParser를 생성하고 정렬된 객체를 Set으로 변환한 다음 parse() 메서드의 인자로 넘긴다.
parse() 메서드 내부에서는 전달받은 Set를 순회하며 가져온 BeanDefinition 정보를 instanceof를 통해 Sub Class Type을 검증한 뒤 해당 정보에 맞게 캐스팅하여 BeanName과 함께 parse()를 호출하며 인자로 넘긴다.
deferredImportSelectorHandler의 process()가 호출된다.
해당 메서드는 deferredImportSelectors 정보를 가져와 정렬한 뒤 forEach를 통해 순회하며 DeferredImportSelectorGroupingHandler register()를 호출하여 해당 정보에 포함된 Annotation Meta 정보와 ConfigurationClass 정보, deferredImport 정보를 호출된 객체 내부에 존재하는 Map에 저장한다.
List<ConfigurationClassParser.DeferredImportSelectorHolder> deferredImports
= this.deferredImportSelectors;
ConfigurationClassParser.DeferredImportSelectorGroupingHandler handler
= ConfigurationClassParser.this.new DeferredImportSelectorGroupingHandler();
deferredImports.sort(ConfigurationClassParser.DEFERRED_IMPORT_COMPARATOR);
deferredImports.forEach(handler::register);
handler.processGroupImports();
private class DeferredImportSelectorGroupingHandler {
private final Map<Object, DeferredImportSelectorGrouping> groupings = new LinkedHashMap<>();
private final Map<AnnotationMetadata, ConfigurationClass> configurationClasses = new HashMap<>();
public void register(DeferredImportSelectorHolder deferredImport) {
Class<? extends Group> group = deferredImport.getImportSelector().getImportGroup();
DeferredImportSelectorGrouping grouping = this.groupings.computeIfAbsent(
(group != null ? group : deferredImport),
key -> new DeferredImportSelectorGrouping(createGroup(group)));
grouping.add(deferredImport);
this.configurationClasses.put(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getConfigurationClass());
}
저장된 정보를 가지고 processGroupImports() 메서드를 호출한다.
앞서 저장된 Map을 순회하면서 getImports() 메서드를 호출한다.
getImports() 메서드는 전달받은 DeferredImportSelectorHolder 타입 객체 정보를 순회한다.
AutoConfigurationImportSelector의 process()를 호출하면서 DeferredImportSelectorHolder의 ConfigurationClass의 Metadate 정보와 importSelector를 전달한다.
주어진 importSelector를 AutoConfigurationImportSelector로 캐스팅하여 getAutoConfigurationEntry() 메서드를 호출한 다음 AutoConfigurationEntry 타입 객체인 autoConfigurationEntry에 저장한다.
저장한 entry의 MetaData를 가져와 ConfigurationClass 타입의 객체를 선언하여 저장한다.
processImports() 메서드를 호출하고 주어진 ConfigurationClass 객체를 importStack이 상속받은 ArrayDeque에 해당 정보를 저장한다.
전달받은 Collection importCandidates 향상된 For문으로 순회한다.
해당 정보는 ImportSelector 또는 ImportBeanDefinitionRegistrar가 아닌 Configuration 정보이기에 해당 정보를 importStack의 LinkedMultiValueMap에 저장하게 된다.
→ 이때 저장되는 정보는 위에서 주어진 ConfigurationClass를 SourceClass로 필터를 거쳐 Converting 된 객체의 Metadata와 enrty의 포함된 Import Class 컬랙션이다.
importCandidates의 요소를 ConfigClass로 변환하고 grouping에 저장되어 있던 exclusionFilter를 전달한 뒤 SourceClass로 컨버팅하고 doProcessConfigurationClass()를 호출한다.
Bean, ComponentScan 등의 어노테이션들 정보가 포함되어 있는지 확인하여 각각의 어노테이션에 맞게 해당 정보를 로딩하거나 파싱 한 뒤 Bean을 생성한다.
@AutoConfigurationPackage?
자동 구성 패키지 정보를 저장하는 AutoConfigurationPackages 클래스의 정보를 가져오는 어노테이션이다.
AutoConfigurationPackages 클래스는 자동 구성 패키지 내의 정의된 Meta-annotation들을 기반으로 정보들을 가져온 뒤 별도의 리스트를 통해 (이후에 참조될) 패키지 이름들을 저장하는 로직을 가지고 있다.
해당 로직을 통해 저장된 패키지 정보들은 이후 beanDefinition으로 저장되게 되는데 이는 Import 된 AutoConfigurationPackages.Registrar.class를 통해 이루어진다.
static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports {
@Override
public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {
register(registry, new PackageImports(metadata).getPackageNames().toArray(new String[0]));
}
@Override
public Set<Object> determineImports(AnnotationMetadata metadata) {
return Collections.singleton(new PackageImports(metadata));
}
}
public static void register(BeanDefinitionRegistry registry, String... packageNames) {
if (registry.containsBeanDefinition(BEAN)) {
BasePackagesBeanDefinition beanDefinition = (BasePackagesBeanDefinition) registry.getBeanDefinition(BEAN);
beanDefinition.addBasePackages(packageNames);
}
else {
registry.registerBeanDefinition(BEAN, new BasePackagesBeanDefinition(packageNames));
}
}
PackageImports(AnnotationMetadata metadata) {
AnnotationAttributes attributes = AnnotationAttributes
.fromMap(metadata.getAnnotationAttributes(AutoConfigurationPackage.class.getName(), false));
List<String> packageNames = new ArrayList<>(Arrays.asList(attributes.getStringArray("basePackages")));
for (Class<?> basePackageClass : attributes.getClassArray("basePackageClasses")) {
packageNames.add(basePackageClass.getPackage().getName());
}
if (packageNames.isEmpty()) {
packageNames.add(ClassUtils.getPackageName(metadata.getClassName()));
}
this.packageNames = Collections.unmodifiableList(packageNames);
}
EnableAutoConfiguration와 관련된 어노테이션들
@AutoConfigureOrder
ApplicationContext에 전달될 자동 구성 클래스 순서를 정의하는 어노테이션이다.
각 Bean의 의존 관계와 DependsOn 어노테이션을 통해 내부적으로 등록 순서가 결정되며 Bean이 만들어지는 것과 주입하는 순서에 대한 속성과는 별개의 어노테이션이다.
@AutoConfigureAfter
인자로 주어진 자동 구성 클래스가 적용된 뒤에 해당 어노테이션이 적용된 자동 구성 클래스를 적용하게끔 하는 어노테이션이다.
@Import
다른 @Configuration 이 적용된 클래스의 Bean Definition을 명시적으로 컨테이너나 구성 클래스에 적용할 수 있도록 한다.
ComponentScan 어노테이션과 유사한 동작 방식을 가지지만, 다수의 구성 클래스를 적용하기 위해서는 모두 명시적으로 작성하여야 된다.
기본적으로 사용하는 이유는 여러 설정을 하나의 클래스에 작성하지 않고 유사성을 따라 분리하여 정의하고 하나의 구성 클래스에서 정보를 집계하여 사용하기 위함이다.
@Configuration
@Import({ AConfig.class, BConfig.class })
public class GroupConfiguration {
}
Spring Boot가 설정해주는 것들 몇 가지 짚어보기
DataSource 자동 초기화
Main 메서드가 호출되고 run 메서드가 실행된다.
run 메서드 실행 중 refreshContext() 메서드가 ConfigurableApplicationContext 타입의 객체를 전달받으며 호출된다.
넘겨받은 객체 타입을 검증하는 refresh(ApplicationContext) 메서드에 전달하여 확인하고 해당 객체 타입의 인자가 전달되지 않는 refresh() 메서드를 호출한다.
메서드 내부적으로 invokeBeanFactoryPostProcessors(BeanFactory); 를 호출한다. 인자로 전달받은 beanFactory에서 PostProcessor 개수를 전달받은 뒤 순회하면서 해당 정보를 ArrayList인 currentRegistryProcessors에 저장한다.
currentRegistryProcessors를 정렬하고 해당 리스트와 beanFactory를 BeanDefinitionRegistry로 Casting 한 다음 invokeBeanDefinitionRegistryPostProcessors() 메서드에 전달한다
내부적으로 전달받은 ArrayList를 순회하며 각각의 PostProcessor 들을 등록하는 절차를 진행한다. postProcessBeanDefinitionRegistry → processConfigBeanDefinitions → ConfigurationClassBeanDifinitionReader에 정보를 넘겨 생성한 뒤 loadBeanDefinitions 메서드를 호출한다.
넘겨받은 Set를 순회하며 loadBeanDefinitionsForConfigurationClass를 호출한다. 해당 메서드는 loadBeanDefinitionsFromRegistrars()를 호출하여 registrar 들의 registerBeanDefinitions() 메서드를 호출하는 절차를 진행한다.
DataSourceInitializationConfiguration 내부에 Regisrar의 registerBeanDefinitions()를 호출하고 해당 로직에서 dataSourceInitializerPostProcessor이라는 이름을 가진 PostProcessor 가 존재하지 않는 경우 DataSourceInitializerPostProcessor.class을 등록하는 로직을 실행한다.
이후 Bean 이 등록되어 초기화 절차를 진행하는데 이때 afterPropertiesSet() 메서드를 호출하여 createSchema()를 통해 DB의 Schema를 등록하는 절차를 진행한다.
위의 로직이 성공하면 initialize()를 호출하여 구성된 Schema에 data.sql 정보를 읽어 등록한다.
sql 파일들을 통해 정상적으로 DB가 구성되고 사용할 수 있게 된다.
내용을 계속 추가하고 있습니다.
Spring vs Spring Boot
[의존성 관리와 설정을 자동으로 해준다! - Starter]
스프링 부트는 스프링 프레임워크의 경량화를 위해 분리된 수많은 Jar 파일을 필요에 맞게 등록하고, 관련 설정을 선언하는 절차없이 기본 설정값으로 제공되는 @Configuration Class들을 통해 빠른 실행을 가능케 하고, Bean에 대한 Builder를 통해 사용자 정의도 쉽게 할 수 있게 하여 빠른 개발 환경 구성을 지원하기 위해 만들어진 것입니다.
내장 톰켓에 대해서도 요청을 관리하기 위해 필요했던 매핑 작업, 서블릿 등록, 컨텍스트 설정들을 구성해주고 있기에 바로 실행하여 결과를 확인할 수 있게 되는 것을 알 수 있습니다.
이것이 Spring과 Spring Boot 제일 큰 차이이며, Spring Boot를 사용해야하는 근본적인 이유임을 알 수 있습니다.
메서드 내에서 사용 가능하며, 로직을 진행하면서 조건에 따라 명시적으로 예외를 던질 때 사용하는 키워드이다. Check Exception은 해당 키워드를 통해 전파시킬 수 없으며 인스턴스만 전달 가능하고 한 번에 여러 예외를 전달할 수 있게끔 작성할 수 없다.
Spring에서는 ExceptionHanler를 이용하여 원하는 처리를 진행할 수 있다.
public void someMethod() {
// Do Something..
if(a < 1) {
throw new RuntimeException();
}
// Do Something
}
// 당연히 Try-catch 문도 이용 가능하다.
try {
throw new RuntimeException("hello");
} catch (RuntimeException exception){
exception.printStackTrace();
}
throws
메서드 시그니쳐에 사용 가능하며, 해당 메서드를 호출하는 클라이언트에게 예외를 던진다.
해당 키워드는 Check Exception도 전달할 수 있으며, 메서드 뒤에 예외 클래스 형태로 정의된다.
쉼표를 이용하여 여러 Exception을 던질 수 있음을 선언할 수 있다.
void userDaoTest_selectOnes() throws SQLException {
ResultSet resultSet = connection.prepareStatement("SELECT * FROM USER WHERE ID = 3")
.executeQuery();
}
void userDaoTest_selectOnes() throws IOException, FileNotFoundException{
// Do Someting..
}
finally
try문, try-catch 문의 과정, 결과와 상관없이 마지막에 꼭 실행하여야 하는 로직을 정의하는 문법, 주로 사용된 Resource에 대해 반납하는 코드를 작성한다.
해당 로직의 경우 하는 일이 많이 없기에 가독성의 대한 큰 문제를 느끼지 못하지만, 복잡한 흐름을 가지기에 로직이 복잡해질수록 가독성이 떨어지게 된다. 추가적으로 반환되어야 할 자원이 많을수록 개발자가 어떠한 자원에 대하여 정리하는 로직을 작성하지 못해 문제를 일으킬 수 있다.
이를 해결하기 위해 JDK 7부터는 AutoCloseable 인터페이스를 구현한 클래스들에 대해 자동적으로 자원을 회수할 수 있는 문법을 제공한다. 이를 try-with-resources 문법이라고 한다.
try-with-resources
해당 방식은 여러 로직을 세미콜론으로 구분하여 선언하게 된다. 해당 방식은 로직이 진행되고, 내부적으로 close() 호출하여 모든 리소스를 반납하게 된다.
Custom Exception을 만들 때에는 해당 예외의 특징을 고려하여 extend를 통해 Exception이나 RuntimeException을 상속받아 작성한다.
개인적으로 해당 Exception에 대해 좀 더 명확한 정보 전달을 위해 유사한 표준 에러를 상속받아 좀 더 구체적인 Custom Exception 들을 작성하고 있다.
// Custom Runtime Exception
public class NoSuchPostException extends NoSuchElementException {
// Do SomeThing..
public NoSuchPostException(String errorMessage) {
super(errorMessage);
}
}
커스텀 예외를 사용한다는 것은 표준 예외에 비해 좀더 명확한 정보를 전달할 수 있음을 의미하지만, 오용하게 될 경우 지나치게 많은 클래스가 만들어짐으로써 메모리의 문제( Metaspace는 상관없으며, Perm gen을 사용하는 경우)와 클래스 로딩 문제가 발생할 수 있다.
그렇기에 그저 이름을 바꿔 구현하는 것보다는 범용 에러를 활용하면서 메시지를 잘 작성하고 꼭 필요한 시점에만 명확한 정보를 추가적으로 제공함으로써 디버그를 진행함에 있어서 도움이 되게끔 잘 활용하여야 한다.
인터페이스는 (구현한) 하위 인스턴스를 참조할 수 있는 타입이며, 해당 인스턴스가 어떠한 행위를 할 수 있는지 클라이언트에게 알려주는 일종의 계약서 역할을 한다.
클라이언트는 해당 행위를 알려주고 구현부는 해당 타입의 인스턴스에게 맡김으로써 정보 은닉을 지킬 수 있다. 이는 반대로 생각한다면 클라이언트는 구현부의 변경에 따른 여파가 없음을 의미한다.
인터페이스를 정의하는 방법?
{Access-Level-Modifier} interface {Name} {
// JDK 7까지는 기본적으로 Static Method를 제외하고 추상 타입의 public Method 만을
// 선언할 수 있다.
// 이 Method는 해당 Interface를 구현하는 Class에서 무조건 Overiding하여야 한다.
public String xxxMethod(String str);
// Access-Level-Modifier 를 작성하지 않고 정의할 수 있으며, 기본 값은 Public이다.
String xxxMethod(String str);
// 상수 정의
// 인터페이스의 용도를 반하는 대표적인 안티패턴이다.
// 상수 필드를 정의하는 것은 해당 타입의 하위 구현체의 구현부를 노출하는 행위이다.
// 클라이언트에게는 필요없는 정보이기도 하다.
static final String name = "Lob!";
}
인터페이스 구현하는 방법
Interface(만) 를 instantiation 할 수 있을까?
public interface SampleInterface {
String xxxMethod(String str);
}
----------
// error: SampleInterface is abstract; cannot be instantiated
SampleInterface sampleInterface = new SampleInterface();
Interface 만으로는 instantiation시킬 수 없으며, 해당 Interface를 Implement 한 Sub Class(Instance)를 통해서만 구현할 수 있다.
Interface의 Abstract Method를 Override한 뒤 생성하는 방식이다.
public class SampleInterfaceImpl implements SampleInterface {
@Override
public String xxxMethod(String str) {
return "Hello "+str;
}
}
----------
SampleInterface sampleInterfaceOfSubClass = new SampleInterfaceImpl();
System.out.println(sampleInterfaceOfSubClass.xxxMethod("lob"));
인터페이스 레퍼런스를 통해 구현체를 사용하는 방법
Interface도 Abstract Class나 Super Class같이 Sub Class를 참조하는 타입으로써 사용할 수 있다.
클래스 상속 관계같이 인터페이스 타입으로 Casting할 경우 인터페이스에 정의된 Method만을 참조하여 사용할 수 있다.
public class SampleInterfaceImpl2 implements SampleInterface {
public String someMethod(String str) {
return "Sub Class Hello "+str;
}
@Override
public String xxxMethod(String str) {
return "Hello "+str;
}
}
SampleInterface sampleInterface1 = (SampleInterface) new SampleInterfaceImpl2();
sampleInterface1.xxxMethod("lob");
// error: cannot find symbol sampleInterface1.someMethod("lob");
sampleInterface1.someMethod("lob");
// 이렇게 Down Casting 하면 사용 가능하다.
((SampleInterfaceImpl2) sampleInterface1).someMethod("lob");
객체는 인터페이스를 사용해 참조하자. (JDK 5+)
이펙티브 자바에서는 적합한 Interface가 존재하는 경우 매개변수뿐만 아니라 반환 값, 변수, 필드 변수에 대한 모든 타입을 Interface로 선언하라고 한다. 이는 하위 구현체들이 모두 Interface 타입으로 참조가 가능하기에, 좀 더 유연한 코드를 작성할 수 있음을 의미한다.
// 좋은 예
// 해당 경우에는 컬랙션 변수가 Param이라고 가정하였을 때 ArrayList, LinkedList, Stack,
// Vector 등이 전달되어도 문제가 발생하지 않는다.
List<String> list = new ArrayList<>();
// 나쁜 예
// 해당 경우에는 구체적인 클래스 타입을 적용하였기에 다른 List 구현체들이 오게될 경우
// 에러가 발생한다.
ArrayList<String> list = new ArrayList<>();
물론 Class가 특별한 기능을 제공하고, 해당 기능을 사용하여야 하는 경우에는 그러지 않아도 된다.
적합한 Interface가 존재하지 않는다면, Class의 계층 구조 중 필요한 기능을 만족하고 추상적인 클래스를 타입으로 사용하자.
인터페이스 상속
Interface는 Interface 끼리만 상속 관계를 연결할 수 있으며, Interface를 이용하여 다중 상속(구현)을 지원할 수 있다.
public interface SampleInterface {
String xxxMethod(String str);
}
public interface SampleInterfaceForDefault {
default String xxxxMethod(String str) {
return "Hello "+str;
}
}
public class SampleInterfaceImpl3 implements SampleInterface, SampleInterfaceForDefault {
@Override
public String xxxMethod(String str) {
return "override Hello! "+str;
}
}
----------
SampleInterfaceImpl3 sampleInterface2 = new SampleInterfaceImpl3();
sampleInterface2.xxxMethod("lob");
sampleInterface2.xxxxMethod("lob");
Interface들을 다중 구현하였을 경우 동일한 메서드 시그니쳐가 존재한다면, Override하여 사용하여야 한다. (그렇지 않다면 컴파일 에러가 발생한다.)
Class와 Interface를 같이 상속, 구현하였을 경우에는 Class에 존재하는 메서드가 우선권을 가진다.
인터페이스의 기본 메소드 (Default Method), 자바 8
JDK 8 이후부터는 Interface에 Static Method를 제공하는 것 말고도 Default Method라는 것이 생기게 되었다. 이는 기존에 사용되던 Interface의 문제점인 한번 배포된 Interface는 수정이 어렵다.라는 것을 해결하기 위하여 추가되었다고 생각한다.
Default Method가 도입된 JDK 8 이후에는 많은 Method들이 추가되었음을 알 수 있다.
이미 배포된 Interface 에 메서드를 추가하게 된다면, 기존에 해당 Interface를 사용하던 모든 프로젝트에서는 개발 중일 때에는 컴파일 에러, 실행 중 인 것들에 대해서는 NoSuchMethod Error가 발생하게 된다.
메서드를 추가한다면?
public interface SampleInterface {
String xxxMethod(String str);
// 해당 메서드가 추가되었다.
void addMethod(String str);
}
----------
// error: <anonymous interfaceexample.InterfaceClient$1> is not abstract and does not override abstract method addMethod(String) in SampleInterface
SampleInterface sampleInterface = new SampleInterface() {
@Override
public String xxxMethod(String str) {
return "Hello "+str;
}
};
// Multiple non-overriding abstract methods found in interface interfaceexample.SampleInterface
// 구현 방식 1 = lambda 방식 (JDK 8+)
SampleInterface sampleInterfaceOfLambda = str -> "Hello "+str;
----------
//Class 'SampleInterfaceImpl3' must either be declared abstract or implement abstract method 'addMethod(String)' in 'SampleInterface'
public class SampleInterfaceImpl3 implements SampleInterface, SampleInterfaceForDefault {
@Override
public String xxxMethod(String str) {
return "override Hello! "+str;
}
}
default 키워드를 사용하여 Method를 추가한 뒤 구현하면 해당 문제가 발생하지 않는다.
추가적으로 default Method도 Public으로 인식되며, Static Method와 달리 재정의가 가능하다.
이는 default Method도 Instance와 같이 가시되며, 런타임 시점에서 Dispatch가 되기 때문이다.
인터페이스의 static 메서드, 자바 8
Interface의 Static Method도 JDK 8 이후에 제공되기 시작하였으며, default Method와 같이 구현부를 가지게 된다.
다른 점은 위에서 이야기하였던
Override가 불가능한 것
Instance가 아닌 Interface와 가시 되며. 컴파일 시점에서 Dispatch 된다는 것
그리고 일반적인 Static Method와 달리 상속되지 않고 Interface Type을 직접 참조하여 호출해야 한다는 것이다.
이는 Interface를 다중 상속을 하였을 경우 발생할 수 있는 문제를 방지하는 조치인 것 같다.
public interface SampleInterface {
String xxxMethod(String str);
default void addMethod(String str) {
System.out.println("Hello "+str);
}
static void addStaticMethod(String str) {
System.out.println("Static Hello "+str);
}
}
----------
SampleInterface.addStaticMethod("lob");
SampleInterface sampleInterface3 = new SampleInterface() {
@Override
public String xxxMethod(String str) {
return "null";
}
// Method does not override method from its superclass
*@Override*
// Inner classes cannot have static declarations
static void addStaticMethod(String str) {
System.out.println("Static Hello "+str);
}
};
해당 메서드도 인터페이스를 구현하지 않고도 Util Method를 이용하고 싶다면 구현하는 방식으로 사용하면 좋을 것 같다.
인터페이스의 private 메서드, 자바 9
private Method가 추가된 이유로는 인터페이스의 static, default Method의 로직을 공통화하고 재사용하기 위함이다. 이는 JDK 8에 발생했던 중복 코드 문제를 해결하게 되었다.
private Method도 Static, default Method 같이 구현부를 가져야한다는 동일한 제약을 가진다.
간단한 예시 코드
JDK 8
default void multiplyAfterAddingNumbers(long num1, long num2) {
long val = num1 + num2;
val = val * val;
System.out.println("result = " + val);
}
default void multiplyAfterSubtractingNumbers(long num1, long num2) {
long val = num1 - num2;
val = val * val;
System.out.println("result = " + val);
}
JDK 9
default void multiplyAfterAddingNumbers(long num1, long num2) {
long val = multiplyNumbers(num1 + num2);
System.out.println("result = " + val);
}
default void multiplyAfterSubtractingNumbers(long num1, long num2) {
long val = multiplyNumbers(num1 - num2);
System.out.println("result = " + val);
}
private long multiplyNumbers(long val) {
return val * val;
}
PreparedStatement는 Statement가 가지고 있던 불필요한 절차, 리소스 사용, Non-Caching 등의 요소들을 최적화한 하위 클래스이다. DB와의 쿼리 성능이 중요한 Server든 아니든간에 유의미한 성능차이를 보이므로, PreparedStatement를 사용하는 것이 좋다.
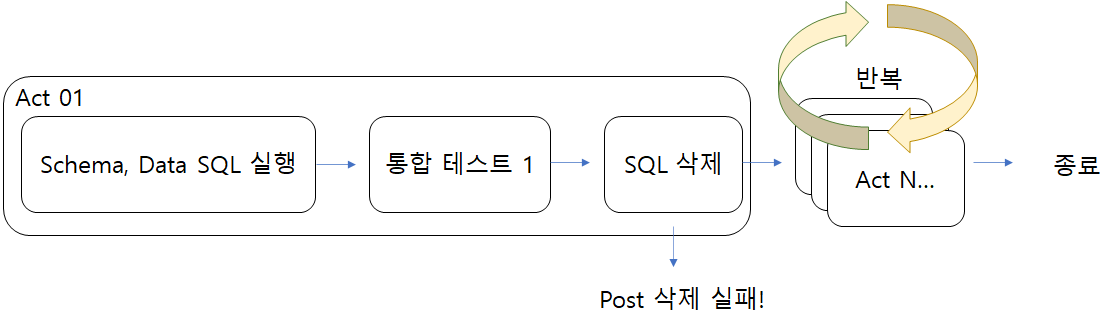
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'postController' defined in file [C:\Users\serrl\Desktop\Mentoring\Somaeja\build\classes\java\main\com\somaeja\post\controller\PostController.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'postService' defined in file [C:\Users\serrl\Desktop\Mentoring\Somaeja\build\classes\java\main\com\somaeja\post\service\PostService.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'postMapper' defined in file [C:\Users\serrl\Desktop\Mentoring\Somaeja\build\classes\java\main\com\somaeja\post\mapper\PostMapper.class]: Unsatisfied dependency expressed through bean property 'sqlSessionFactory'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'sqlSessionFactory' defined in class path resource [com/somaeja/common/config/PersistenceConfig.class]: Unsatisfied dependency expressed through method 'sqlSessionFactory' parameter 0; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'dataSource' defined in class path resource [org/springframework/boot/autoconfigure/jdbc/DataSourceConfiguration$Hikari.class]: Initialization of bean failed; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.boot.autoconfigure.jdbc.DataSourceInitializerInvoker': Invocation of init method failed; nested exception is org.springframework.jdbc.datasource.init.ScriptStatementFailedException: Failed to execute SQL script statement #1 of URL [file:/C:/Users/serrl/Desktop/Mentoring/Somaeja/build/resources/main/schema.sql]: CREATE TABLE POST ( POST_ID INTEGER PRIMARY KEY auto_increment, USER_ID INTEGER NOT NULL, LOCATION_ID INTEGER NOT NULL, IMAGE_ID INTEGER NOT NULL, TITLE VARCHAR(255) NOT NULL, CONTENT VARCHAR(255) NOT NULL, PRICE VARCHAR(255) NOT NULL, IS_NEGOTIABLE TINYINT(1) NOT NULL, IS_DIRECTTRADE TINYINT(1) NOT NULL, CREATEDATE VARCHAR(255) NOT NULL, MODIFYDATE VARCHAR(255) NOT NULL ); nested exception is org.h2.jdbc.JdbcSQLSyntaxErrorException: Table "POST" already exists; SQL statement:
CREATE TABLE POST ( POST_ID INTEGER PRIMARY KEY auto_increment, USER_ID INTEGER NOT NULL, LOCATION_ID INTEGER NOT NULL, IMAGE_ID INTEGER NOT NULL, TITLE VARCHAR(255) NOT NULL, CONTENT VARCHAR(255) NOT NULL, PRICE VARCHAR(255) NOT NULL, IS_NEGOTIABLE TINYINT(1) NOT NULL, IS_DIRECTTRADE TINYINT(1) NOT NULL, CREATEDATE VARCHAR(255) NOT NULL, MODIFYDATE VARCHAR(255) NOT NULL ) [42101-200]
at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:797)
at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:227)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.autowireConstructor(AbstractAutowireCapableBeanFactory.java:1356)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1203)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:556)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:516)
at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:324)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:322)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:897)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:879)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:551)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:758)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:750)
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:405)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:315)
at org.springframework.boot.test.context.SpringBootContextLoader.loadContext(SpringBootContextLoader.java:120)
at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContextInternal(DefaultCacheAwareContextLoaderDelegate.java:99)
at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContext(DefaultCacheAwareContextLoaderDelegate.java:124)
... 88 more