
티스토리 뷰
Prometheus 개요
Prometheus는 오픈소스 기반의 모니터링 시스템으로 Service discovery pattern을 통해 데이터 수집대상을 발견하고 주기적으로 풀링하여 매트릭 데이터를 수집합니다.

수집된 매트릭 정보들은 로컬 디스크에 있는 시계열 데이터베이스에 저장되어 Prometheus의 도메인 특화 언어인 PromQL을 통해 빠르게 검색할 수 있습니다.
Prometheus는 매트릭 수집을 위한 서버나 컨테이너 구성이 불필요(Single host)하며, 클라이언트가 매트릭 푸시를 위해 CPU를 사용할 필요도 없습니다. (Metric Push를 통한 응답 병목이나 서버 부하를 예방합니다.)
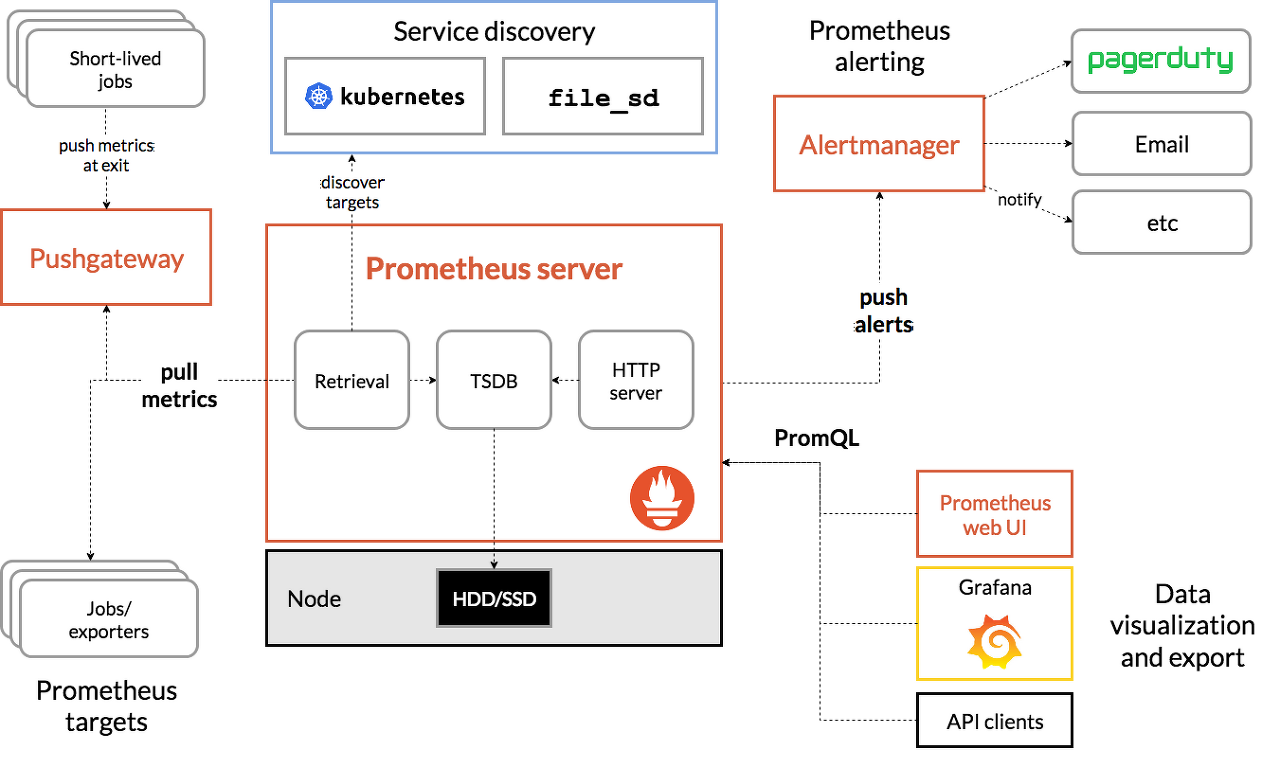
부가적으로 중앙 집중식 구성 방식과 관리 콘솔을 제공하기에 설치나 사용이 매우 쉽습니다.
Prometheus의 이점
- Kubernetes 환경에서 설치하기가 쉽고 Grafana와 같은 Tool과 연동이 쉬우며 많은 Dashboard 템플릿들이 오픈소스로 공유되고 있습니다.
- 기존에 구현된 다양한 Exporter를 제공합니다. (매트릭 수집을 위한 클라이언트들)
- 또한 각 언어별 Client library를 제공함으로써 쉽게 Counter나 Custom 매트릭 들을 뽑아낼 수 있습니다.
- Spring의 경우 Boot Actuator 모듈을 통해서 Hikari pool, memory 매트릭을 얻을 수 있습니다.
- 또한 각 언어별 Client library를 제공함으로써 쉽게 Counter나 Custom 매트릭 들을 뽑아낼 수 있습니다.
- 수집된 매트릭은 용량을 압축하여 저장하고 시계열 데이터베이스의 뛰어난 성능을 기반으로 많은 매트릭을 빠르게 조회할 수 있습니다.
Prometheus의 한계, 주의할 점
- 풀링을 기반으로 매트릭을 수집하기 때문에 장애 발생을 빠르게 감지하는 것에는 어려움이 있습니다.
- 풀링하는 순간의 매트릭 정보만 가지고 있기 때문에 근삿값만을 알 수 있습니다.
- 싱글 호스트 아키텍처 구조의 한계로 인해 이중화나 클러스터링을 적용하기가 매우 어렵습니다.
- 저장용량이 부족한 경우에는 설치된 서버의 디스크 용량을 늘릴 수 밖에 없습니다.
- 다른 오픈소스를 같이 사용하는 상황은 제외
- 저장용량이 부족한 경우에는 설치된 서버의 디스크 용량을 늘릴 수 밖에 없습니다.
- 이중화 구성 시에는 Replication을 하지않고, 두개의 Prometheus를 띄워 같은 목록을 풀링시키고 저장하는 방법을 사용하게 됩니다.
- Thanos라는 오픈소스를 사용하여 매트릭 정보의 집계하고, 스케일링 가능한 스토리지에 저장하여 특정 프로메테우스의 장애로 인한 매트릭 소실 등을 방지할 수 있습니다.
- Prometheus는 매트릭 정보를 효율적으로 다루기 위해(Read, Write, Sampling 등) Memory에 Buffering을 진행합니다. 메모리와 관련된 직접적인 설정을 할 수 없기 때문에 여러 작업에서 사용하는 리소스의 량을 계산하여 램을 증설하거나 Cardinality가 높은(Selectivity가 낮은) label을 수집하지 않거나 수집 주기를 늘리는 식으로 대처하여야 합니다.
- 관련 설정 중 다룰 수 있는 것은 페이지 캐시의 크기만 존재하며, 다른 값은 버전이 업데이트 됨에 따라서 달라집니다.
이제 Prometheus를 통해 매트릭 정보를 뽑아올 Target Application 들을 구현해보겠습니다.
Sample Application Archtecture
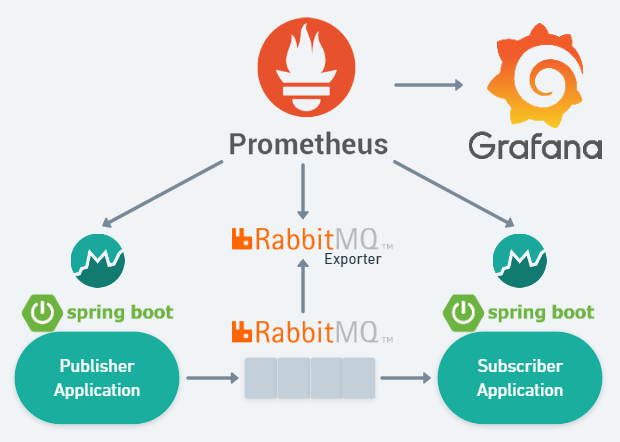
Publisher Application 구현
프로젝트 생성
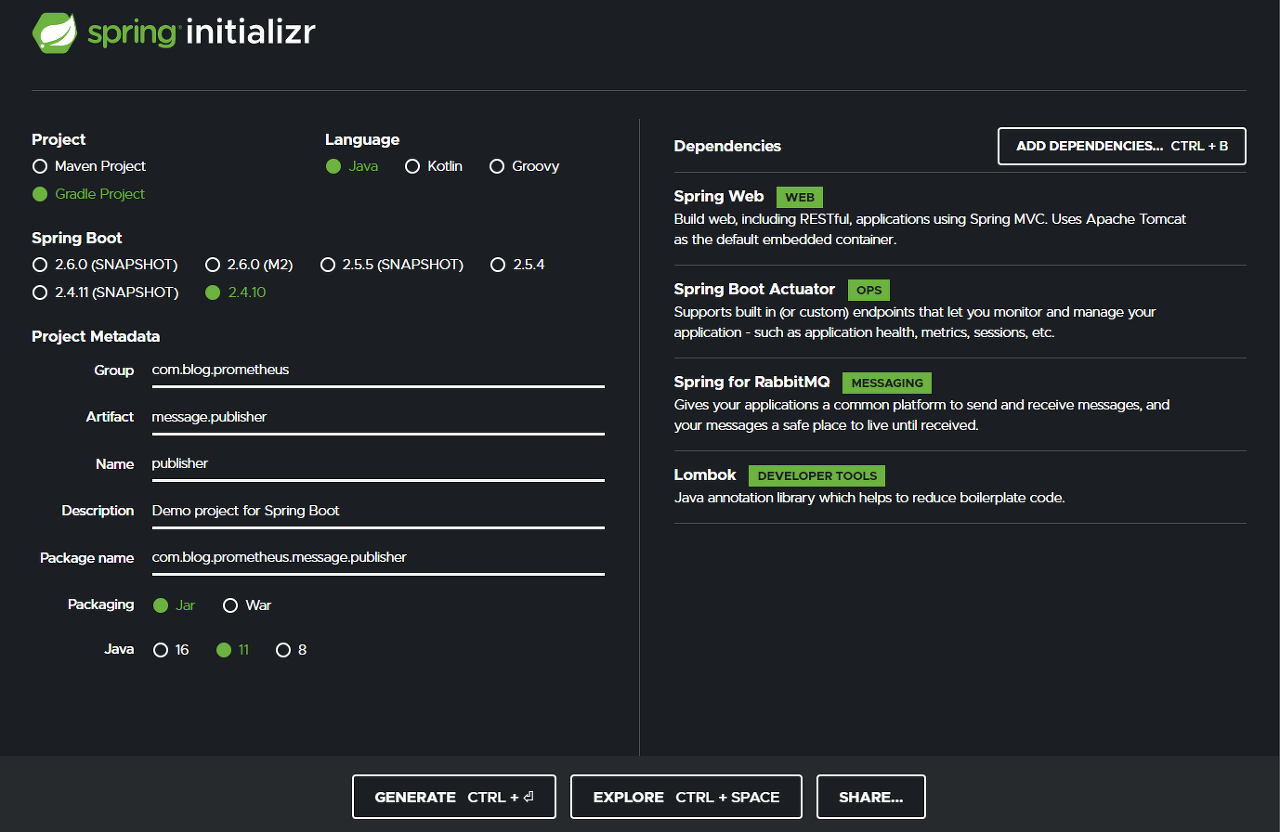
우선은 RabbitMQ 메세지를 생산할 Publisher Application을 구현해보겠습니다.
제가 사용할 Spring Actuator Module에는 내장된 micrometer 라이브러리가 존재하는데, 이것은 JVM 기반의 매트릭 정보를 다루는 인터페이스의 역할을 합니다. (Facade Pattern)
해당 라이브러리를 통해 Prometheus에서 사용하는 매트릭 정보를 받기 위해서는 별도 의존성을 추가해야 합니다.
implementation 'io.micrometer:micrometer-registry-prometheus'
Application yml
# yml 출처 : https://meetup.toast.com/posts/237
# 추가한 micrometer 라이브러리을 이용하여 metric 데이터 응답을 제공할 API를 설정합니다.
management:
endpoints:
web:
exposure:
include: prometheus # {protocol}://{host:port}/prometheus
metrics:
tags:
application: ${spring.application.name} # metric 정보에 대한 라벨링 설정
endpoint:
health:
show-details: always
spring:
application:
name: "publisher_application" # 라벨링 설정 값
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
logging:
level:
root: info
server:
port: 8080사용할 RabbitMQ 설정과 Logging, port 설정을 진행하고 마무리합니다.
RabbitMQConfiguration
@Configuration
public class RabbitMQConfiguration {
@Bean
public Queue queue() {
return new Queue("event-queue", true);
}
@Bean
public DirectExchange exchange() {
return new DirectExchange("event");
}
@Bean
public Binding binding(Queue queue, DirectExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with("event-pay");
}
@Bean
public Jackson2JsonMessageConverter messageConverter() {
return new Jackson2JsonMessageConverter(new ObjectMapper());
}
@Bean
public RabbitTemplate rabbitTemplate(final ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setMessageConverter(messageConverter());
return rabbitTemplate;
}
}연결된 RabbitMQ Container에 설정할 Queue와 DirectExchange, Routing Key를 설정하고, 객체를 Json 형태로 Converting 할 수 있게 Jackson2JsonMessageConverter를 설정합니다.
ScheduledConfiguration
@Configuration
@EnableScheduling
public class ScheduledConfiguration implements SchedulingConfigurer {
// Scheduled 과 같은 스케줄링 작업에 대한 구성 정보를 설정하는 Registrar
@Override
public void configureTasks(ScheduledTaskRegistrar registrar) {
final ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(3);
taskScheduler.setThreadNamePrefix("event-");
taskScheduler.initialize();
registrar.setTaskScheduler(taskScheduler);
}
}메세지를 생산하는 역할을 하는 Scheduled이 설정된 메서드를 최대 몇 개까지 실행할지 그리고 실행할 때 사용되는 스레드 정보를 커스텀할 수 있는 ThreadPoolTaskScheduler를 설정합니다.
Application
예제의 단순화를 위해서 별도의 Component를 정의하지 않고 Application Class에서 코드를 작성합니다.
단순한 예제 코드이므로 따로 설명을 하진 않겠습니다.
@Slf4j
@SpringBootApplication
@RequiredArgsConstructor
public class PublisherApplication {
private final RabbitTemplate rabbitTemplate;
private static final Random generator;
static {
generator = new Random();
}
public static void main(String[] args) {
SpringApplication.run(PublisherApplication.class, args);
}
@Scheduled(fixedRate = 5000) // fixedRate 는 작업을 실행한 시점부터 다음 작업 수행 시간을 측정한다.
public void publishEvent() {
final int userId = generator.nextInt(10);
final LocalDateTime eventTime = LocalDateTime.now();
final PayEvent payEvent = PayEvent.of(userId, "Transaction finished", eventTime.toString());
log.info("{}", payEvent);
rabbitTemplate.convertAndSend("event", "event-pay", payEvent);
}
}
----------
// 사용될 도메인 모델
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class PayEvent {
private long userId;
private String message;
private String eventTime;
protected PayEvent(long userId, String message, String eventTime) {
this.userId = userId;
this.message = message;
this.eventTime = eventTime;
}
public static PayEvent of(long userId, String message, String eventTime) {
return new PayEvent(userId, message, eventTime);
}
@Override
public String toString() {
return "PayEvent{" +
"userId=" + userId +
", message='" + message + '\'' +
", eventTime='" + eventTime + '\'' +
'}';
}
}PayEvent 라는 객체를 생성하여 메시지 큐에 넣을 Publisher Application 구현이 완료되었습니다. 이제 해당 요청을 In-memory DB에 저장하는 단순한 Subscriber Application을 구현해봅니다.
Subscriber Application 구현
프로젝트 생성
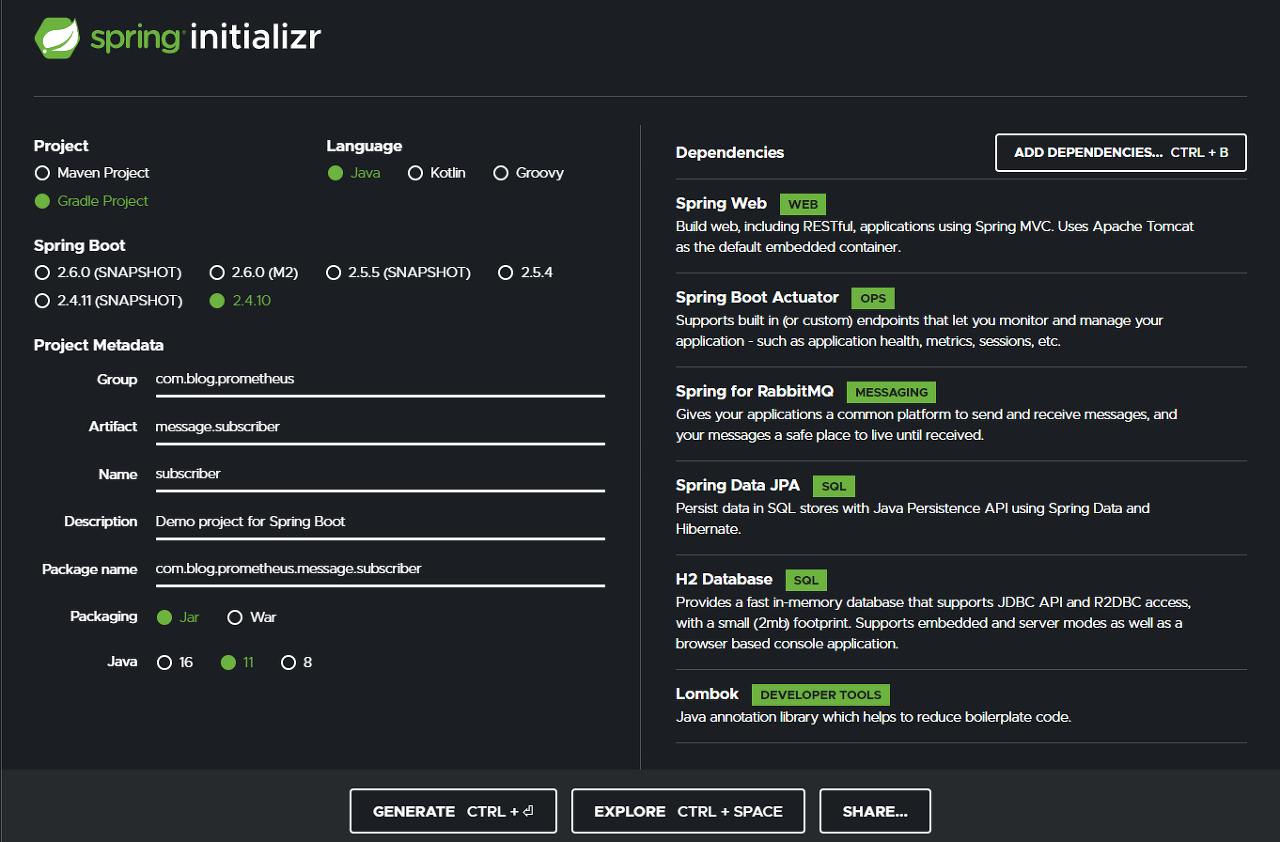
이미지와 별개로 Publisher application과 동일하게 micrometer 관련 의존성을 추가합니다.
Application yml
# yml 출처 : https://meetup.toast.com/posts/237
management:
endpoints:
web:
exposure:
include: prometheus
metrics:
tags:
application: ${spring.application.name}
endpoint:
health:
show-details: always
spring:
application:
name: "subscriber_application"
datasource:
url: jdbc:h2:mem:testdb
username: sa
driver-class-name: org.h2.Driver
h2:
console:
enabled: true
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
jpa:
hibernate:
ddl-auto: update
properties:
show-sql: true
format_sql: true
open-in-view: false
logging:
level:
root: info
server:
port: 8081기존 Application과 동일하게 micrometer 설정을 진행하고, Datasource, JPA 설정을 진행합니다.
RabbitMQConfiguration
@Configuration
public class RabbitMQConfiguration {
@Bean
public Jackson2JsonMessageConverter messageConverter() {
return new Jackson2JsonMessageConverter(new ObjectMapper());
}
@Bean
public RabbitTemplate rabbitTemplate(final ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setMessageConverter(messageConverter());
return rabbitTemplate;
}
}Queue 관련 설정은 별도로 진행하지 않으며, 위와 같이 JSON 데이터를 객체로 변환하기 위해 ObjectMapper를 추가합니다.
Application
@Slf4j
@RequiredArgsConstructor
@SpringBootApplication
public class SubscriberApplication {
private final PayEventRepository payEventRepository;
public static void main(String[] args) {
SpringApplication.run(SubscriberApplication.class, args);
}
@RabbitListener(queues = "event-queue")
public void subscribeEvent(PayEvent payEvent) {
log.info("{}", payEvent);
payEventRepository.save(payEvent);
}
}
----------
// 여기서는 JPA를 통한 영속화를 위해 Entity로 정의합니다.
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class PayEvent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private long userId;
private String message;
private String eventTime;
public PayEvent(long userId, String message, String eventTime) {
this.userId = userId;
this.message = message;
this.eventTime = eventTime;
}
@Override
public String toString() {
return "PayEvent{" +
"userId=" + userId +
", message='" + message + '\'' +
", eventTime='" + eventTime + '\'' +
'}';
}
}
----------
// 어딘가 있을 JPA Repository...
public interface PayEventRepository extends JpaRepository<PayEvent, Long> {
}@RabbitListener annotation을 통해 queue를 구독한 상태로 전달되는 PayEvent를 JPA로 영속화하는 단순한 Application입니다.
이제 Sample Application 코드들을 구현하였으니, RabbitMQ, Exporter, Prometheus와 Grafana를 등록하기 위해 yml file과 docker-compose.yml을 작성합니다.
RabbitMQ, Prometheus, Grafana 구성
Prometheus.yml
docker-compose.yml를 실행하기 전에 우선 Prometheus 정보를 설정합니다.
해당 yml은 https://katacoda.com/courses/prometheus/getting-started와 튜토리얼을 참고하여 작성하였습니다.
global:
scrape_interval: 10s
scrape_configs:
- job_name: "publisher_application"
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ["host.docker.internal:8080"]
- job_name: "subscriber_application"
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ["host.docker.internal:8081"]
- job_name: "rabbitmq_exporter"
metrics_path: "/metrics"
static_configs:
- targets: ["host.docker.internal:9419"]RabbitMQ_exporter의 매트릭 정보 응답 port는 9419가 default port 입니다.
docker-compose.yml
version: '3'
networks:
back:
services:
rabbitmq:
image: rabbitmq:3-management
container_name: rabbitmq
environment:
- RABBITMQ_NODENAME:rabbitmq
ports:
- "5672:5672"
- "15672:15672"
networks:
- back
rabbitmq-exporter:
image: kbudde/rabbitmq-exporter
container_name: rabbitmq-exporter
environment:
- RABBIT_URL=http://rabbitmq:15672
depends_on:
- rabbitmq
ports:
- "9419:9419"
networks:
- back
prometheus-1:
image: prom/prometheus
container_name: prometheus-1
environment:
- --config.file=/etc/prometheus/prometheus.yml
volumes:
- C:\.\.\.\config\prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
networks:
- back
grafana:
image: grafana/grafana
depends_on:
- prometheus-1
ports:
- "3000:3000"
networks:
- back해당 yml의 bind mounting은 windows를 기준으로 작성되었습니다.
기본적으로 RabbitMQ exporter는 RabbitMQ의 container와 네트워크 인터페이스를 공유하는 방식으로 동작합니다. https://github.com/kbudde/rabbitmq_exporter
- 하지만 저는 네트워크를 공유하지 않고 개별적으로 네트워크를 구분하였습니다.
- 네트워크를 공유하는 것은 https://herrenofficial.github.io/devops/2020/04/26/prometheus-with-grafana-1.html 를 참고해보시면 좋을 것 같습니다.
이제 해당 compose file을 실행하면 {http}://{host:port}를 통해 Prometheus와 Grafana Admin으로 접근할 수 있습니다.
- Grafana의 기본 계정 정보는 admin / admin입니다.
Prometheus Dashboard
상단 메뉴바의 Status를 클릭하여 Targets 목록을 선택하면 yml에서 구성한 정보를 기준으로 구성된 Target Application 목록을 볼 수 있습니다.
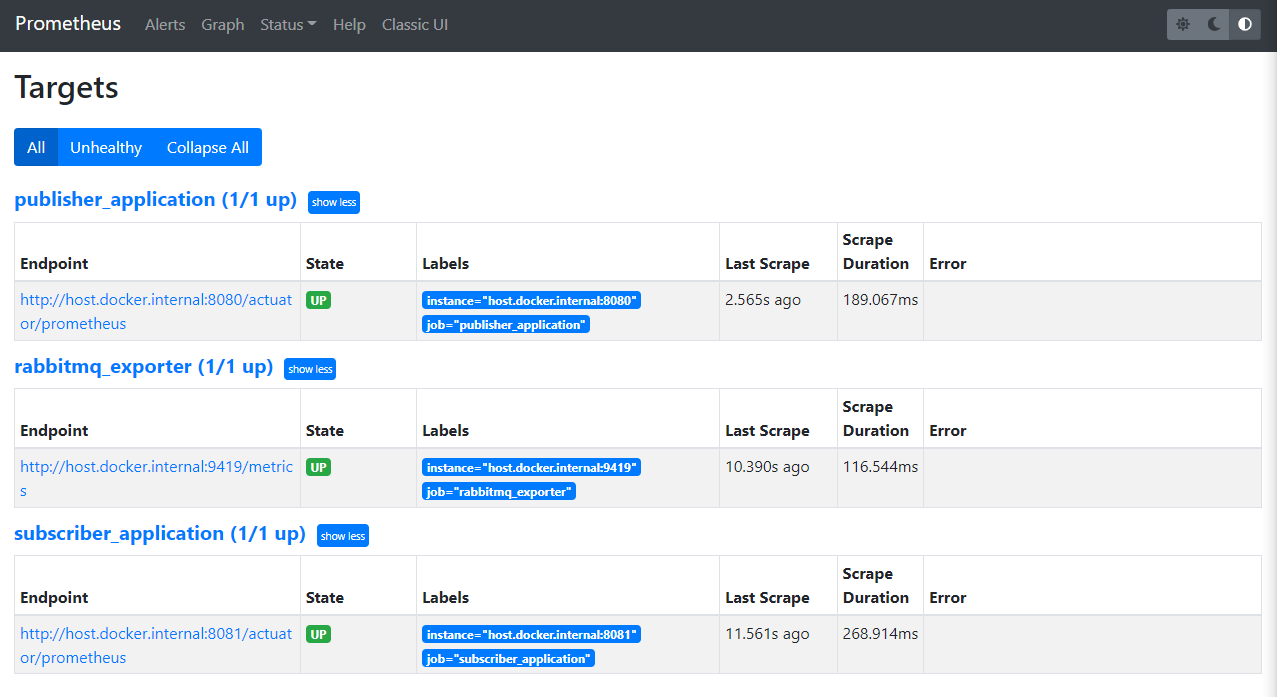
이렇게 등록된 Target Application의 상태(health-check)와 마지막으로 pulling한 시간 정보 등을 간단하게 확인할 수 있습니다.
그럼 이제 Grafana에 접속하여 패널을 추가하고 가시화되는 데이터를 확인해보겠습니다.
- 해당 글은 연동하는 것에만 의의를 두었기에 후술된 내용은 다른 튜토리얼을 참고하는 것이 좋을 수 있습니다.
Grafana Dashboard
이제 Prometheus의 매트릭 정보를 가져오기 위해 Data source를 설정해보겠습니다.
- 좌측 상단 수직 메뉴바에서 톱니바퀴(Configuration)를 클릭하고 data source를 선택합니다.
- 그다음 Add data source 버튼을 클릭합니다.
- Time series databases 항목에서 Prometheus를 선택합니다.
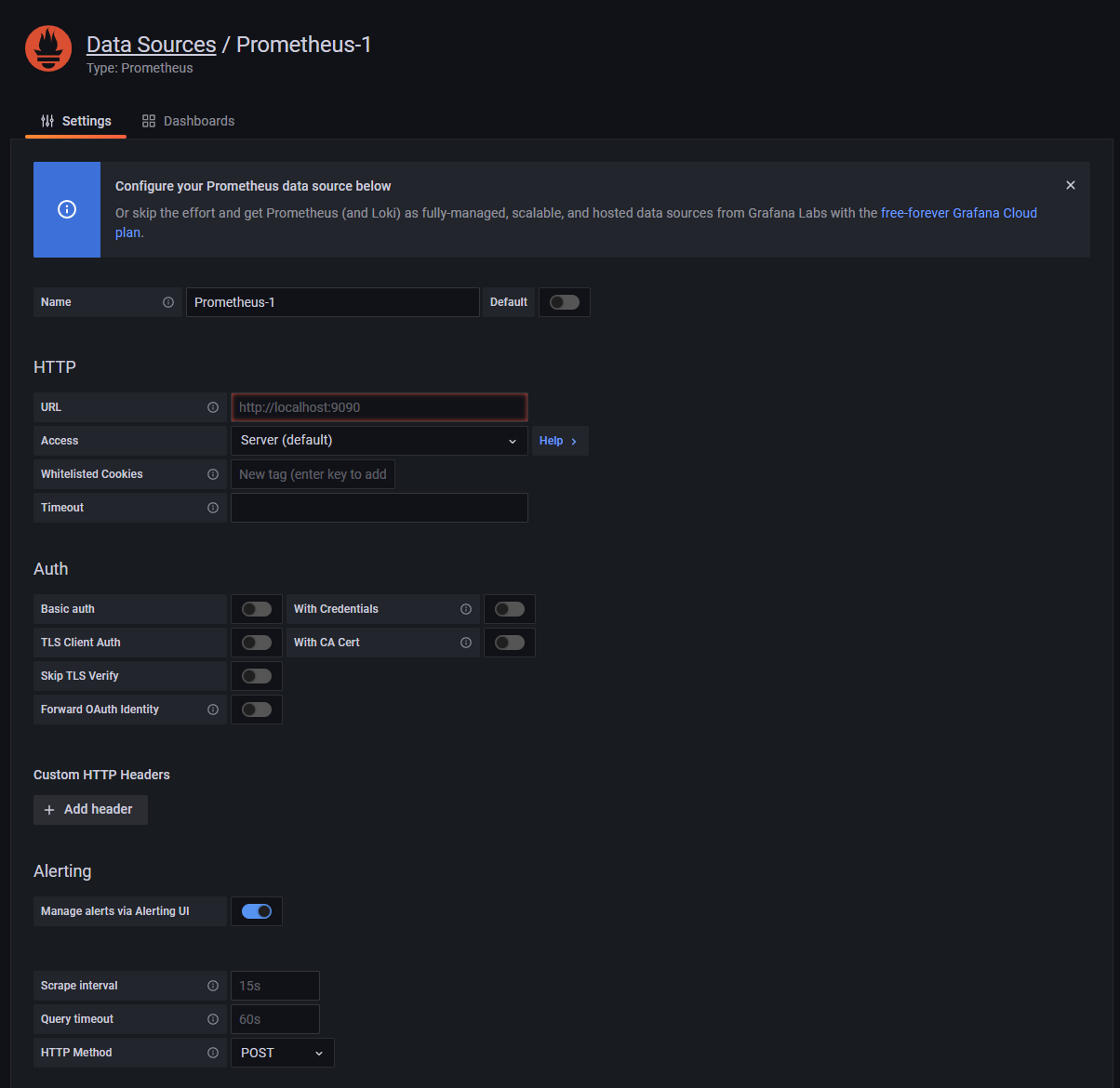
이제 Prometheus가 실행되는 host 정보를 HTTP 항목의 URL에 입력하시고 맨 밑에 Save & test를 눌러 연결 상태를 확인한 다음 저장합니다.
Dashboard 설정하기
이제 메인화면으로 돌아와서 좌측 메뉴바의 + 버튼을 클릭하고 Dashboard를 선택합니다.
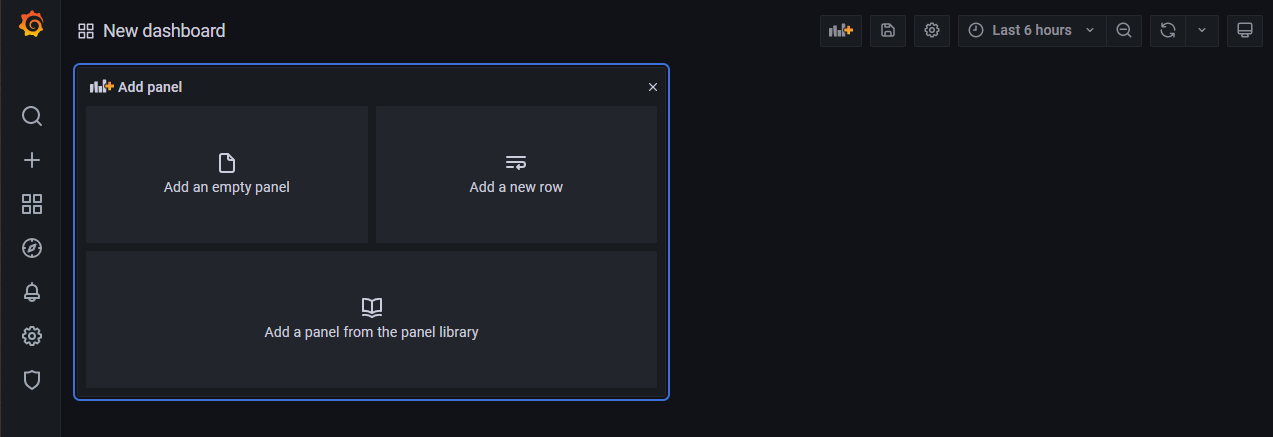
Add a new row를 선택하여 하나의 row를 만들고 좌측 상단의 그래프와 + 가 합쳐진 버튼을 눌러서 하나 더 추가합니다. (이름은 임의로 정해주세요.)
다시 방금 그 버튼을 눌러서 Add an empty panel을 선택합니다.
이제 현재 JVM 메모리 사용량을 나타내는 jvm_memory_used_bytes metric를 이용해 Time series를 만듭니다. 별도 설정이 없다면 위에서 만든 pub/sub application 정보가 모두 등록됩니다.
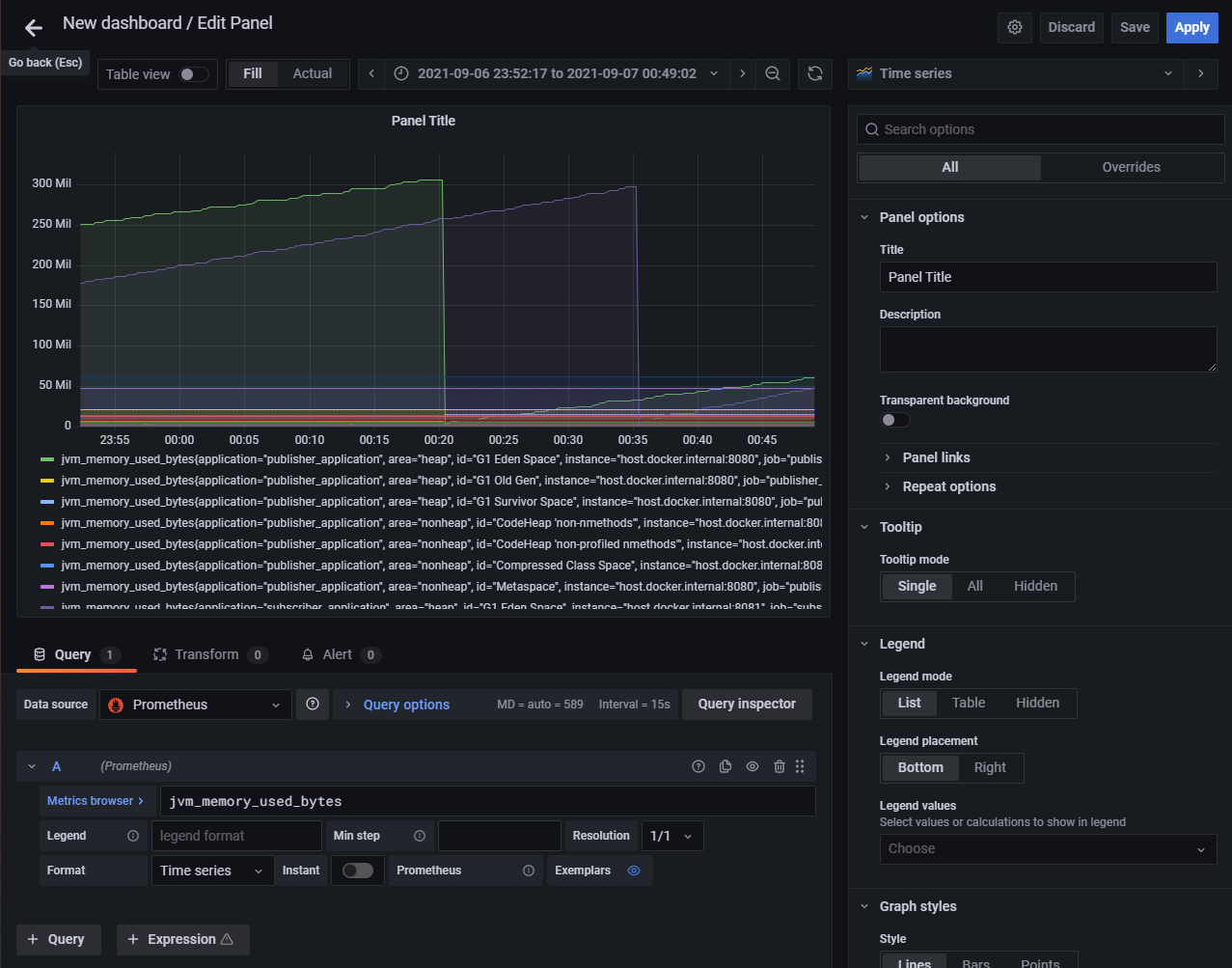
설정이 완료되었다면 Apply를 누릅니다.
여기서부터 기존에 존재하던 내용은 필요가 없어보여 제거했습니다. 그대신 몇가지 PromQL 예시를 보여드리는 것으로 변경하였습니다.
MySQL QPS (Query Per Second)
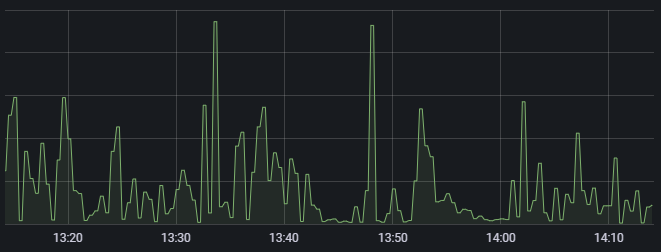
rate(mysql_global_status_queries[{Time}])PromQL의 Range Vector 중 하나인 rate를 이용하여 특정 기간{Time} 동안 평균 값 혹은 변동 폭을 연산해 가시화할 수 있습니다.
MySQL Slow Queries
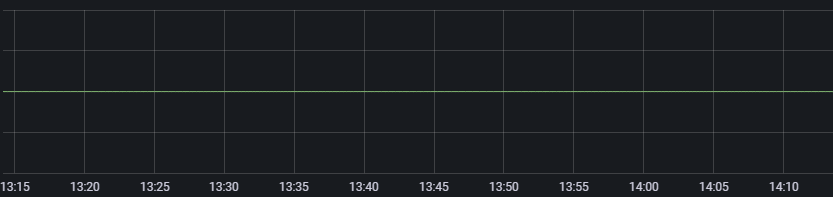
irate(mysql_global_status_slow_queries[Time])PromQL의 Range Vector 중 하나인 irate를 사용하면 특정 기간의 순간적인 수치 증가율을 연산해 가시할 수 있습니다.
MySQL Connection Error
rate(mysql_global_status_connection_errors_total[Time])
MySQL available connections
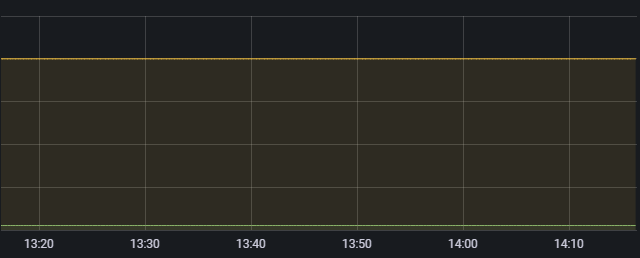
100 * mysql_global_status_threads_connected / mysql_global_variables_max_connections
RabbitMQ memory used

rate(node_mem_used[{Time}])
RabbitMQ messages published total
rate(queue_messages_published_total[{Time}])
등등 Exporter에서 제공하는 다양한 메트릭을 이용하여 다양한 성능 지표를 확인할 수 있습니다.
그리고 만약 혼자서 구성하는 것이 어렵다면, https://grafana.com/grafana/dashboards/ 에서 완성된 대시보드를 가져와 사용할 수 있습니다.
제공되는 메트릭 정보는 각 (Exporter에 대한) Github Project를 들어가셔서 readme 를 확인하시면 됩니다.
타노스를 통한 HA 구성 등의 내용들은 더 열심히 공부를 한 뒤에 새로운 글을 작성하거나 보강하도록 하겠습니다.
이 게시글의 결과물은 https://github.com/Lob-dev/The-Joy-Of-Java/tree/main/Sample-Spring-Boot-Prometheus 에서 보실 수 있습니다.
참고 자료
'Programming' 카테고리의 다른 글
| 소소한 글 : Spring AOP 예제를 차근차근 구현해보기 (0) | 2021.09.22 |
|---|---|
| 소소한 글 : Base Column를 정의할 때 @MappedSuperclass 와 embedded Type 중 무엇을 사용해야 할까? (2) | 2021.09.11 |
| RabbitMQ Message Queue 및 Message 보존 설정과 Fair Dispatch (0) | 2021.08.21 |
| AMQP Frame Structure, Component, Types (0) | 2021.08.21 |
| ZGC (4) | 2021.06.16 |
- Total
- Today
- Yesterday
- Data Locality
- rabbitmq
- Url
- JDK Dynamic Proxy
- Switch
- mybatis
- JPA
- RESTful
- Distributed Cache
- cglib
- JVM
- 게으른개발자컨퍼런스
- URN
- 게으른 개발자 컨퍼런스
- URI
- spring AOP
- Cache Design
- 근황
- Local Cache
- 소비자 관점의 api 설계 패턴과 사례 훑어보기
- hypermedia
- THP
- RPC
- AMQP
- spring
- java
- lambda
- Global Cache
- configuration
- HTTP
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |